转自 新智元
– 1 –
回顾 2018 年机器学习的进展,2018年6月 DeepMind 团队发表的论文 “Relational inductive biases, deep learning, and graph networks”,是一篇重要的论文,引起业界热议。
随后,很多学者沿着他们的思路,继续研究,其中包括清华大学孙茂松团队。他们于2018年12月,发表了一篇综述,题目是“Graph neural networks: A review of methods and applications”。
2019年1月,俞士纶教授团队,也写了一篇综述,这篇综述的覆盖面更全面,题目是“A Comprehensive Survey on Graph Neural Networks”。

俞士纶教授团队综述GNN,来源:arxiv
DeepMind 团队的这篇论文,引起业界这么热烈的关注,或许有三个原因:
- 声望:自从 AlphaGo 战胜李世乭以后,DeepMind 享誉业界,成为机器学习业界的领军团队,DeepMind 团队发表的论文,受到同行普遍关注;
- 开源:DeepMind 团队发表论文 [1] 以后不久,就在 Github 上开源了他们开发的软件系统,项目名称叫 Graph Nets [4];
- 主题:声望和开源,都很重要,但是并不是被业界热议的最主要的原因。最主要的原因是主题,DeepMind 团队研究的主题是,如何用深度学习方法处理图谱。
– 2 –
图谱 (Graph) 由点 (Node) 和边 (Edge) 组成。
图谱是一个重要的数学模型,可以用来解决很多问题。
譬如我们把城市地铁线路图当成图谱,每个地铁站就是一个点,相邻的地铁站之间的连线就是边,输入起点到终点,我们可以通过图谱的计算,计算出从起点到终点,时间最短、换乘次数最少的行程路线。
又譬如 Google 和百度的搜索引擎,搜索引擎把世界上每个网站的每个网页,都当成图谱中的一个点。每个网页里,经常会有链接,引用其它网站的网页,每个链接都是图谱中的一条边。哪个网页被引用得越多,就说明这个网页越靠谱,于是,在搜索结果的排名也就越靠前。
图谱的操作,仍然有许多问题有待解决。
譬如输入几亿条滴滴司机行进的路线,每条行进路线是按时间排列的一连串(时间、GPS经纬度)数组。如何把几亿条行进路线,叠加在一起,构建城市地图?
不妨把地图也当成一个图谱,每个交叉路口,都是一个点,连接相邻的两个交叉路口,是一条边。
貌似很简单,但是细节很麻烦。
举个例子,交叉路口有很多形式,不仅有十字路口,还有五角场、六道口,还有环形道立交桥——如何从多条路径中,确定交叉路口的中心位置?

日本大阪天保山立交桥,你能确定这座立交桥的中心位置吗?
– 3 –
把深度学习,用来处理图谱,能够扩大我们对图谱的处理能力。
深度学习在图像和文本的处理方面,已经取得了巨大的成功。如何扩大深度学习的成果,使之应用于图谱处理?
图像由横平竖直的像素矩阵组成。如果换一个角度,把每个像素视为图谱中的一个点,每个像素点与它周边的 8 个相邻像素之间都有边,而且每条边都等长。通过这个视角,重新审视图像,图像是广义图谱的一个特例。
处理图像的诸多深度学习手段,都可以改头换面,应用于广义的图谱,譬如 convolution、residual、dropout、pooling、attention、encoder-decoder 等等。这就是深度学习图谱处理的最初想法,很朴实很简单。
虽然最初想法很简单,但是深入到细节,各种挑战层出不穷。每种挑战,都意味着更强大的技术能力,都孕育着更有潜力的应用场景。
深度学习图谱处理这个研究方向,业界没有统一的称谓。
强调图谱的数学属性的团队,把这个研究方向命名为 Geometric Deep Learning。孙茂松团队和俞士纶团队,强调神经网络在图谱处理中的重要性,强调思想来源,他们把这个方向命名为 Graph Neural Networks。DeepMind 团队却反对绑定特定技术手段,他们使用更抽象的名称,Graph Networks。
命名不那么重要,但是用哪种方法去梳理这个领域的诸多进展,却很重要。把各个学派的目标定位和技术方法,梳理清楚,有利于加强同行之间的相互理解,有利于促进同行之间的未来合作。
– 4 –
俞士纶团队把深度学习图谱处理的诸多进展,梳理成 5 个子方向,非常清晰好懂。
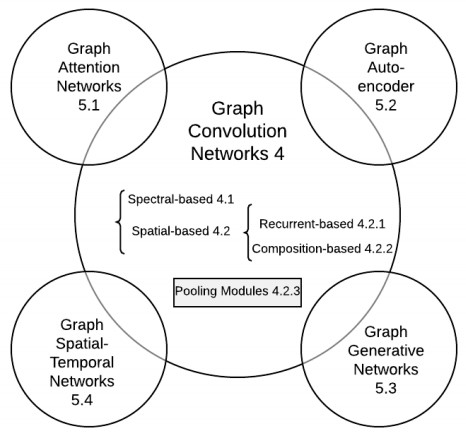
俞士纶团队把深度学习图谱处理梳理成 5 个子方向,来源:论文 A Comprehensive Survey on Graph Neural Networks
- Graph Convolution Networks
- Graph Attention Networks
- Graph Embedding
- Graph Generative Networks
- Graph Spatial-temporal Networks
先说 Graph Convolution Networks (GCNs)。
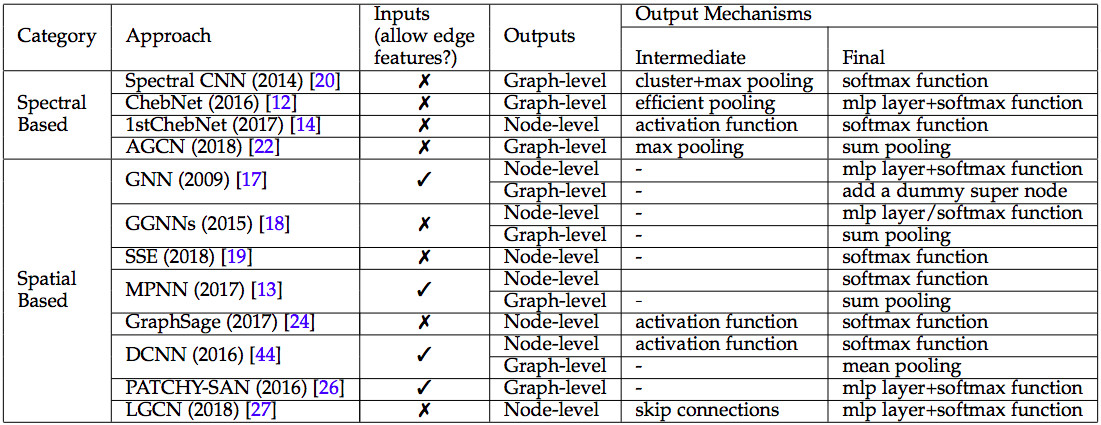
GCN 类别汇总,来源:论文 A Comprehensive Survey on Graph Neural Networks
GCN 把 CNN 诸般武器,应用于广义图谱。CNN 主要分为四个任务,
- 点与点之间的融合。在图像领域,点与点之间的融合主要通过卷积技术 (convolution) 来实现。在广义图谱里,点与点之间的关系,用边来表达。所以,在广义图谱里,点点融合,有比卷积更强大的办法。Messsage passing [5] 就是一种更强大的办法。
- 分层抽象。CNN 使用 convolution 的办法,从原始像素矩阵中,逐层提炼出更精炼更抽象的特征。更高层的点,不再是孤立的点,而是融合了相邻区域中其它点的属性。融合邻点的办法,也可以应用于广义图谱中。
- 特征提炼。CNN 使用 pooling 等手段,从相邻原始像素中,提炼边缘。从相邻边缘中,提炼实体轮廓。从相邻实体中,提炼更高层更抽象的实体。CNN 通常把 convolution 和 pooling 交替使用,构建结构更复杂,功能更强大的神经网络。对于广义图谱,也可以融汇 Messsage passing 和 Pooling,构建多层图谱。
- 输出层。CNN 通常使用 softmax 等手段,对整张图像进行分类,识别图谱的语义内涵。对于广义图谱来说,输出的结果更多样,不仅可以对于整个图谱,输出分类等等结果。而且也可以预测图谱中某个特定的点的值,也可以预测某条边的值。
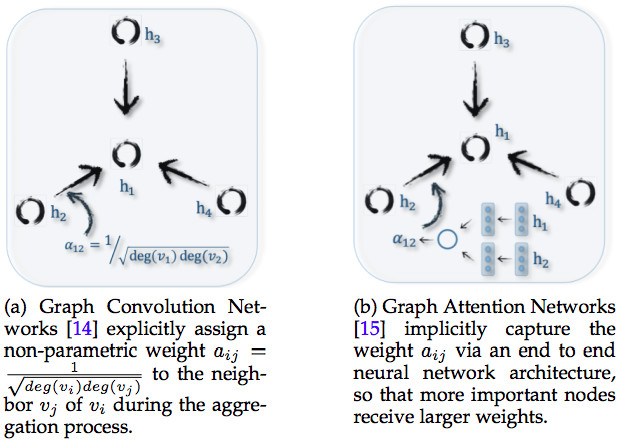
GCN 和Graph Attention Networks 的区别 来源:论文 A Comprehensive Survey on Graph Neural Networks
Graph Attention Networks 要解决的问题,与 GCN 类似,区别在于点点融合、多层抽象的方法。
Graph Convolution Networks 使用卷积方式,实现点点融合和分层抽象。Convolution 卷积方式仅仅适用于融合相邻的点,而 attention 聚焦方式却不限于相邻的点,每个点可以融合整个图谱中所有其它点,不管是否相邻,是否融合如何融合,取决于点与点之间的关联强弱。
Attention 能力更强大,但是对于算力的要求更高,因为需要计算整个图谱中任意两个点之间的关联强弱。所以 Graph Attention Networks 研究的重点,是如何降低计算成本,或者通过并行计算,提高计算效率。
– 5 –
Graph Embedding 要解决的问题,是给图谱中每个点每条边,赋予一个数值张量。图像不存在这个问题,因为像素天生是数值张量。但是,文本由文字词汇语句段落构成,需要把文字词汇,转化成数值张量,才能使用深度学习的诸多算法。
如果把文本中的每个文字或词汇,当成图谱中的一个点,同时把词与词之间的语法语义关系,当成图谱中的一条边,那么语句和段落,就等同于行走在文本图谱中的一条行进路径。
如果能够给每个文字和词汇,都赋予一个贴切的数值张量,那么语句和段落对应的行进路径,多半是最短路径。
有多种实现 Graph Embedding 的办法,其中效果比较好的办法是 Autoencoder。用 GCN 的办法,把图谱的点和边转换成数值张量,这个过程称为编码 (encoding),然后通过计算点与点之间的距离,把数值张量集合,反转为图谱,这个过程称为解码 (decoding)。通过不断地调参,让解码得到的图谱,越来越趋近于原始图谱,这个过程称为训练。
Graph Embedding 给图谱中的每个点每条边,赋予贴切的数值张量,但是它不解决图谱的结构问题。
如果输入大量的图谱行进路径,如何从这些行进路径中,识别哪些点与哪些点之间有连边?难度更大的问题是,如果没有行进路径,输入的训练数据是图谱的局部,以及与之对应的图谱的特性,如何把局部拼接成图谱全貌?这些问题是 Graph Generative Networks 要解决的问题。
Graph Generative Networks 比较有潜力的实现方法,是使用 Generative Adversarial Networks (GAN)。
GAN 由生成器 (generator) 和辨别器 (discriminator) 两部分构成:1. 从训练数据中,譬如海量行进路径,生成器猜测数据背后的图谱应该长什么样;2. 用生成出来的图谱,伪造一批行进路径;3. 从大量伪造的路径和真实的路径中,挑选几条路径,让辨别器识别哪几条路径是伪造的。
如果辨别器傻傻分不清谁是伪造路径,谁是真实路径,说明生成器生成出的图谱,很接近于真实图谱。
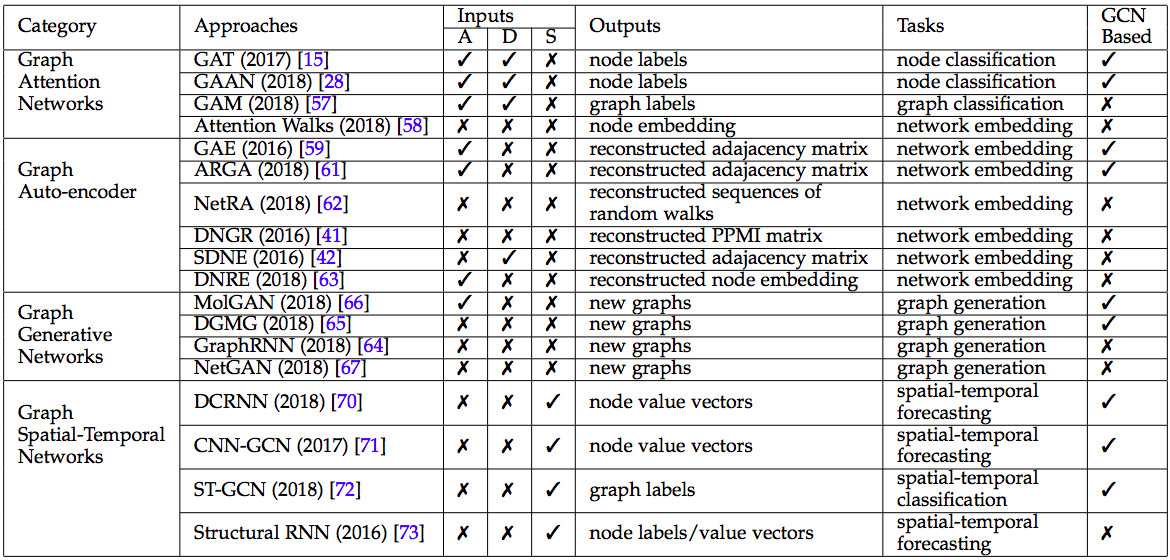
GCN 以外的其他 4 种图谱神经网络,来源:论文 A Comprehensive Survey on Graph Neural Networks
– 6 –
以上我们讨论了针对静态图谱的若干问题,但是图谱有时候是动态的,譬如地图中表现的道路是静态的,但是路况是动态的。
如何预测春节期间,北京天安门附近的交通拥堵情况?解决这个问题,不仅要考虑空间 spatial 的因素,譬如天安门周边的道路结构,也要考虑时间 temporal 的因素,譬如往年春节期间该地区交通拥堵情况。这就是 Graph Spatial-temporal Networks 要解决的问题之一。
Graph Spatial-temporal Networks 还能解决其它问题,譬如输入一段踢球的视频,如何在每一帧图像中,识别足球的位置?这个问题的难点在于,在视频的某些帧中,足球有可能是看不见的,譬如被球员的腿遮挡了。
解决时间序列问题的通常思路,是 RNN,包括 LSTM 和 GRU 等等。
DeepMind 团队在 RNN 基础上,又添加了编码和解码 (encoder-decoder) 机制。
– 7 –
在 DeepMind 团队的这篇论文里[1],他们声称自己的工作,“part position paper, part review, and part unification”,既是提案,又是综述,又是融合。这话怎么理解?

DeepMind联合谷歌大脑、MIT等机构27位作者发表重磅论文,提出“图网络”(Graph network),将端到端学习与归纳推理相结合,有望解决深度学习无法进行关系推理的问题。
前文说到,俞士纶团队把深度学习图谱处理的诸多进展,梳理成 5 个子方向:1) Graph Convolution Networks、2) Graph Attention Networks、3) Graph Embedding、4) Graph Generative Networks、5) Graph Spatial-temporal Networks。
DeepMind 团队在 5 个子方向中着力解决后 4 个方向,分别是 Graph Attention Networks、Graph Embedding、Graph Generative Networks 和 Graph Spatial-temporal Networks。他们把这四个方向的成果,“融合”成统一的框架,命名为 Graph Networks。
在他们的论文中,对这个四个子方向沿途的诸多成果,做了“综述”,但是并没有综述 Graph Convolution Networks 方向的成果。然后他们从这四个子方向的诸多成果中,挑选出了他们认为最有潜力的方法,形成自己的“提案”,这就是他们开源的代码 [4]。
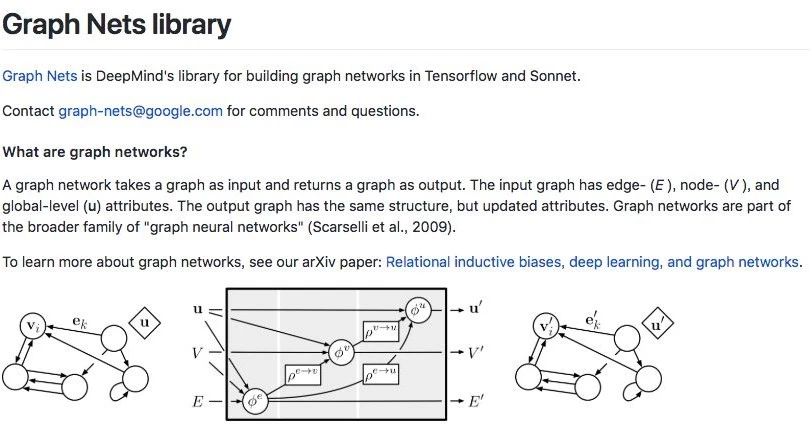
DeepMind在2018年10月开源的Graph Nets library,用于在TensorFlow中构建简单而强大的关系推理网络。来源:github.com/deepmind/graph_nets
虽然论文中,他们声称他们的提案解决了四个子方向的问题,但是查看他们开源的代码,发现其实他们着力解决的是后两个子方向,Graph Attention Networks 和 Graph Spatial-temporal Networks。
DeepMind 的思路是这样的:首先,把 [5] 的 message passing 点点融合的机制,与 [6] 图谱全局的聚焦机制相结合,构建通用的 graph block 模块;其次,把 LSTM 要素融进 encoder-decoder 框架,构建时间序列机制;最后,把 graph block 模块融进 encoder-decoder 框架,形成 Graph Spatial-temporal Networks 通用系统。
– 8 –
为什么 DeepMind 的成果很重要?事关四件大事。
一、深度学习过程的解释
从原理上讲,深度学习譬如 CNN 的成果,来自于对图像的不断抽象。也就是,从原始的像素矩阵中,抽象出线段。从首尾相连的相邻线段中,抽象出实体的轮廓。从轮廓抽象出实体,从实体抽象出语义。
但是,如果窥探 CNN 每一层的中间结果,实际上很难明确,究竟是哪一层的哪些节点,抽象出了轮廓,也不知道哪一层的哪些节点,抽象出了实体。总而言之,CNN 的网络结构是个迷,无法明确地解释网络结构隐藏的工作过程的细节。
无法解释工作过程的细节,也就谈不上人为干预。如果 CNN 出了问题,只好重新训练。但重新训练后的结果,是否能达到期待的效果,无法事先语料。往往按下葫芦浮起瓢,解决了这个缺陷,却引发了其它缺陷。
反过来说,如果能明确地搞清楚 CNN 工作过程的细节,就可以有针对性地调整个别层次的个别节点的参数,事先人为精准干预。
二、小样本学习
深度学习依赖训练数据,训练数据的规模通常很大,少则几万,多大几百万。从哪里收集这么多训练数据,需要组织多少人力去对训练数据进行标注,都是巨大挑战。
如果对深度学习的过程细节,有更清晰的了解,我们就可以改善卷积这种蛮力的做法,用更少的训练数据,训练更轻巧的深度学习模型。
卷积的过程,是蛮力的过程,它对相邻的点,无一遗漏地不分青红皂白地进行卷积处理。
如果我们对点与点之间的关联关系,有更明确的了解,就不需要对相邻的点,无一遗漏地不分青红皂白地进行卷积处理。只需要对有关联的点,进行卷积或者其它处理。
根据点与点之间的关联关系,构建出来的网络,就是广义图谱。广义图谱的结构,通常比 CNN 网络更加简单,所以,需要的训练数据量也更少。
三、迁移学习和推理
用当今的 CNN,可以从大量图片中,识别某种实体,譬如猫。
但是,如果想给识别猫的 CNN 扩大能力,让它不仅能识别猫,还能识别狗,就需要额外的识别狗的训练数据。这是迁移学习的过程。
能不能不提供额外的识别狗的训练数据,而只是用规则这样的方式,告诉电脑猫与狗的区别,然后让电脑识别狗?这是推理的目标。
如果对深度学习过程有更精准的了解,就能把知识和规则,融进深度学习。
从广义范围说,深度学习和知识图谱,是机器学习阵营中诸多学派的两大主流学派。迄今为止,这两大学派隔岸叫阵,各有胜负。如何融合两大学派,取长补短,是困扰学界很久的难题。把深度学习延伸到图谱处理,给两大学派的融合,带来了希望。
四、空间和时间的融合,像素与语义的融合
视频处理,可以说是深度学习的最高境界。
- 视频处理融合了图像的空间分割,图像中实体的识别,实体对应的语义理解。
- 多帧静态图像串连在一起形成视频,实际上是时间序列。同一个实体,在不同帧中所处的位置,蕴含着实体的运动。运动的背后,是物理定律和语义关联。
- 如何从一段视频,总结出文本标题。或者反过来,如何根据一句文本标题,找到最贴切的视频。这是视频处理的经典任务,也是难度超大的任务。
参考文献
- Relational inductive biases, deep learning, and graph networks,https://arxiv.org/abs/1806.01261
- Graph neural networks: A review ofmethods and applications,https://arxiv.org/abs/1812.08434
- A Comprehensive Survey on Graph Neural Networks,https://arxiv.org/abs/1901.00596
- Graph nets,https://github.com/deepmind/graph_nets
- Neural message passing for quantum chemistry,https://arxiv.org/abs/1704.01212
- Non-local neural networks,https://arxiv.org/abs/1711.07971