转自 AI前线
AI 前线导读: 深度学习在图像分类,机器翻译等领域都展示了其强大的能力,但是在因果推理方面,深度学习依然是短板,图神经网络在因果推理方面有巨大的潜力,有望成为 AI 的下一个拐点。DeepMind 公司最近开源了其 GraphNet 算法库,各大巨头公司也纷纷投入大量资源研究图神经网络,本文是 AI 前线第 68 篇论文导读,下面我们来深入了解图神经网络背后的原理和其强大的表征能力。
摘 要
图神经网络(GNNs)广泛应用于图的表征学习,其遵循邻域聚合框架,通过递归聚合和转换相邻节点的特征向量来计算节点的表征向量。已经提出了许多 GNN 的变体,并在节点和图形分类任务上取得比较好的结果。然而,尽管 GNN 使图形表征学习发生了革命性的变化,但是,对其表示属性和局限性的理解还很有限。
在这里,本论文提出了一个在分析 GNN 捕获不同图结构表现力的理论框架。本论文的描述了各种流行的 GNN 变体的判别能力,如 Graph Convolutional Networks(图卷积神经网络) 和 GraphSAGE,并表明他们无法学会区分某些简单的图结构。然后,本论文开发了一个简单的体系结构,可以证明其在 GNNs 类中是最具表现力的,并且它和 Weisfeiler-Lehman(图同构测试) 方法一样强大。在许多图分类基准测试上,通过经验验证了该理论发现,并证明本论文的模型达到了最佳的性能。介 绍
学习图结构数据,例如:分子、社会、生物和金融网络等,需要有效的表征图的结构。最近,研究者们对使用 Graph Neural Network(GNN) 方法来对图进行表征学习产生了极大的兴趣。GNN 大部分都遵循循环递归邻域聚合(或者消息传递)的模式,其中每个节点聚合其相邻节点的特征向量以计算其新的特征向量。在 k 轮聚合迭代后,通过其转换的特征向量来表示该节点,该向量捕获节点的 k-hop 网络邻节点的结构信息。然后,可以通过 pooling 来获得整个图结构的表征,例如对图中所有节点的表征向量求和。许多基于不同 neighborhod aggregation 的 GNN 变体和 graph-level 的 pooling scheme 已经被许多学者提出。
根据经验,这些 GNNs 已经在许多任务中达到最佳的性能,如节点分类,链接预测和图分类。然而,新 GNN 的设计主要是基于经验直觉,启发式和实验试错。对于 GNN 的性质和局限性,目前理论层面的解释还比较少。GNN 的表征能力的正式分析还是有限的。
本论文提出了一个分析 GNN 表征能力的理论框架。从形式上描述了不同 GNN 变体在学习表征和区分各种图结构方面的表现力。该框架是受 GNNs 和 WL 测试(Weisfeiler-Lehman 图同构测试)紧密联系的启发,WL 测试是以其强大的区分各种图结构能力而闻名。与 GNNs 相似,WL 测试通过聚合给定节点的邻近节点的特征向量迭代更新其特征向量。WL 测试的强大之处是其注入聚合(injective aggregation)更新,它映射不同节点的邻近节点到不同的特征向量。主要观点是,如果 GNN 的聚合模式具有高度的表现力和能够为注入函数建模的话,它就同 WL 测试一样具有强大的区分能力。
为了数学形式化上述观点,首先抽象出一个节点的邻近节点的特征向量作为多重集,该集合中可能有重复元素。然后,在 GNNS 中的领域聚合(neighbor aggregation)可以抽象为多集上的函数。我们严格学习不同多集函数的变体,并从理论上描述其识别能力,即不同的聚合函数可以区分不同的多重集。越具有区分力的多重集函数,GNN 的潜在表征能力就越强。
本论文的主要结果总结如下:
1)我们发现在区分图结构方面,GNN 跟 WL 测试能力一样强大。
2)我们发现在建立领域聚合(neighbor aggregation)和图池函数(graph pooling)的情况下,得到的 GNN 和 WL 测试一样强大。
3)我们识别无法通过流行的 GNN 变体区分的图结构,例如 GCN(Kipf&Welling,2017)和 GraphSAGE(Hamilton 等,2017a),并且我们对基于 GNN 模型可以捕获的各种图结构进行了精确的描述。
4)我们开发了一个简单的神经网络架构,图同构网络(Graph Isomorphism Network)GIN,并证明其判别 / 表征能力等同于 WL 测试。
在图分类数据集上,通过实验验证我们的理论,其中 GNN 的表达能力对于捕获图结构至关重要。特别是,我们对基于各种聚合函数的 GNN 性能进行了对比。我们的结果证实了最强大的 GNN(我们的图同构网络 GIN)具有很强的表征能力,可以近乎完美的拟合训练数据,然而较弱的 GNN 变体有严重的欠拟合问题。此外,在许多图分类的基准测试集上,它的表征能力和性能优于其他的 GNNs。预备知识
首先,我们总结一些常见的 GNN 模型,顺便介绍一下相关数学符号的含义。假设 G = (V, E) 表示一个图,图的节点向量用 X(v) 表示,其中,v ∈ V 。有两个比较感兴趣的任务:(1)节点分类,其中每个节点 v ∈ V 都有一个相关的标签 y(v),目标是学习节点 v 的表征向量 h(v),节点 v 的标签可以被函数 y(v)=f(h(v)) 所预测。(2)图分类,其中给定一组图{G1, …, GN }⊆ G 及其标签{y1, …, yN } ⊆ Y,我们的目标是学习一个表征向量 h(G),它有助于预测整个图的标签 y(G) = g(h(G))。 图神经网络
GNNs 利用图结构和节点特征 X(v) 来学习一个节点的表征向量 h(v),或者整个图的表征向量 h(G)。
新式的 GNNs 都遵循领域聚合(neighborhood aggregation)策略,其中我们通过聚合它的邻近节点的表征向量来迭代更新节点的表征向量。在 k 次迭代后,节点的表征可以在它的 k-hop 网络邻居中捕获结构信息。形式上,GNN 的第 k 层是:

其中,h{k}(v) 是节点 v 在第 k 的迭代 / 层的特征向量。我们初始化 h{0}(v)=X(v),N(v) 是与 v 节点邻近的一组节点。在 GNNs 中选择函数 AGGREGATE{k}(·) 和 COMBINE{k}(·) 非常关键。已经提出了许多用于聚合的体系结构。在 GraphSAGE 的 pooling 变体(Hamilton et al., 2017a),AGGREGATE 函数形式如下:

其中,W 是可以学习的矩阵,MAX 表示一个 element-wise 的 max-pooling。在 GraphSAGE 的 COMBINE 步是一个线性映射的连接 W·[h{k-1}(v)|a{k}(v)]。在图卷积网络中(GCN)(Kipf & Welling, 2017),element-wise 的 mean pooling 被替代,AGGREGATE 和 COMBINE 步集成在一体如下:

许多其他的 GNNs 可以类似的表示为 Eq. 2.1 (Xu et al., 2018; Gilmer et al., 2017)。
对于节点分类问题,最后一次迭代的节点表征向量 h{K}(v) 用来做预测。对于图分类问题,READOUT 函数从最后一次迭代中聚合节点特征来获取整个图的表征向量 h(G):

READOUT 函数可以是一个简单的置换不变函数,例如求和或者 graph-level 级别的 pooling 函数 (Ying et al., 2018; Zhang et al., 2018)。 Weisfeiler-Lehman 测试
图同构问题指的是验证两个图在拓扑结构上是否相同。这是一个具有挑战性的问题:因为现在很难知道计算的时间复杂度。WL(Weisfeiler-Lehman)测试是一种非常有效的一测试图同构的方法,它可以区分各种图。
在 1 维的情况下,它类似于在 GNN 中的领域聚合。假设每个节点都有一个分类标签,WL 测试(1)迭代聚合节点标签和他们的邻近节点,(2)将聚合的标签 hash 成唯一的新标签。如果在某些迭代中两个图的节点标签不同,则该算法判定它们是不同的。
基于 WL 试验,Shervashidze 等人(2011)提出了 WL 子树内核来测量图之间的相似性。内核使用在 WL 测试不同迭代中的节点标签计数作为图的特征向量。直观的来看,在 WL 测试的第 k 次迭代中,一个节点的标签表征该根节点的高度为 k 的子树结构(Figure 1)。因此,WL 子树所考虑的图的特征本质上是图中不同根子树的计数。
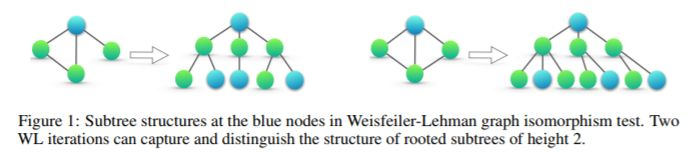
理论框架:概述
我们首先概述了分析 GNNs 表达能力的框架。GNN 递归地更新每个节点的特征向量,以捕获其周围其他节点的网络结构和特征,即其根子树结构(图 1)。在本文中,我们假设节点输入特征是一个宇宙内可数的数。对于有限图,我们可以递归地证明在任何固定模型的深层节点特征向量也是一个宇宙内可数的数。为了简化符号,我们可以为每个特征向量分配一个唯一的标签∈{a,b,c……}。 然后,一组相邻节点的特征向量形成多重集:同一元素可以出现多次,因为不同的节点可以具有相同的特征向量。
多重集定义:多重集是集合的一个广义概念,它允许其元素有多个实例。更正式地讲,多重集是一个二元组 X =(S,m),其中 S 是由其不同元素组成的 X 的基础集合,而 m:S→N(≥1) 给出了元素的多样性。
为了分析 GNN 的表达能力,我们分析了 GNN 何时将两个节点映射到嵌入空间中的相同位置。直观地说,最强大的 GNN 仅当两个节点具有相同的子树结构,并且在对应的节点上具有相同的特征时,才会将它们映射到相同的位置。由于子树结构是通过节点邻域递归定义的(图 1),因此当 GNN 将两个邻域映射到相同的嵌入时,我们可以递归地减少我们的分析。最强大的 GNN 永远不会将两个不同的邻域(即,特征向量的多重集)映射到相同的位置。这意味着它的聚合方案是单射的。 因此,我们将 GNN 的聚合方案抽象为其神经网络可以表示的多重集合上的一类函数,并分析它们是否能够表示单射的多重集函数。
接下来,我们使用这种推理开发一个最强大的 GNN。 在第 5 节中,我们研究了流行的 GNN 变体,并发现它们的聚合方案本质上不是单射的,因此功能较弱,但它们可以捕获图形的其他有趣属性。构建强大的图神经网络
理想情况下,GNN 能够(1)通过将它们映射到嵌入空间中的不同位置来区分不同的图结构,以及(2)在嵌入空间中捕获它们的结构相似性。在本文中,我们主要关注第一部分,我们将简要讨论第二部分。然而,将不同的图映射到不同的嵌入空间的能力意味着可以解决图同构问题。
在我们的分析中,通过一个稍微弱一点的标准来描述 GNN 的表达能力:魏斯费勒 – 雷曼(WL)图同构测试,除少数特例外,该测试通常工作得很好,特别是规则图(Cai 等人,1992;Douglas,2011;Evdokimov&Ponomarenko,1999)。
引理 2. 设 G1 和 G2 为任何非同构图。如果一个图神经网络 A: G → R(d) 遵循领域聚合方案,将 G1 和 G2 映射到不同的嵌入,Weisfeiler-Lehman 图同构检验也判定 G1 和 G2 不是同构的。
因此,在区分不同图方面任何基于聚合的 GNN 都至多与 WL 测试一样强大。一个自然的问题是,在原则上是否存与 WL 测试一样强大的 GNN? 我们在定理 3 中得到的答案是肯定的:如果邻居聚合和图池化函数是单射的,那么得到的 GNN 就像 WL 测试一样强大。
定理 3. 设 A:G→R(d) 是一个遵循邻域聚合方案的 GNN。 通过足够的迭代,如果满足以下条件,则 A 可以将通过 Weisfeiler-Lehman 测试的图 G1 和 G2 为非同构图映射到不同的嵌入:
a)A 每次迭代聚合更新节点特征向量

b)A 的图级别的 readout 函数,运行在节点特征的多重集上{h(k)(v)},是一个单射函数。
在可数集上,单射性很好地描述了一个函数是否保留了输入的区别性。在不可数集上,节点特征是连续的,内射性和判别性的概念被“削弱”。在本文中,我们假设输入节点特征来自可数集。鉴于输入节点特征的可计数性假设,人们可能会问,GNN 更深层的节点特征的可数性是否仍然适用? 引理 4 表示是,即可数性可以跨层传播。
引理 4. 假设输入特征空间 X 是可数的,g(k) 是由 GNN 的第 k 层参数化的函数,k=1,..,L。其中,g(1) 被定义在有限多重集 X ⊂ X 上,g(k) 的范围,节点的隐含特征 h{k}(v) 空间,在 k=1,…,L 都是可数的。
在这里,除了区分不同的图之外,还值得讨论 GNN 的一个重要好处,也就是说,捕捉图结构的相似性。注意,WL 测试中的节点特征向量本质上是一种独热编码(one-hot 编码),因此不能捕获子树之间的相似性。相反,满足定理 3 标准的 GNN,通过学习将子树嵌入低维空间来推广 WL 测试。这使得 GNN 不仅可以区分不同的结构,而且可以学习将相似的图结构映射到相似的嵌入,并捕获图结构之间的依赖关系。捕捉节点标签的结构相似性对泛化有帮助,特别是在不同的图中当子树的共现稀疏或存在噪声边和节点特征时(Yanardag 和 Vishwanathan,2015)。图异构网络(GIN)
接下来,我们开发了一个可证明满足定理 3 中条件的模型,从而推广了 WL 测试。 我们将结果体系结构命名为 Graph Isomorphism Network(GIN)。为了模拟领域聚合的单射多重集函数,我们发展了一个“深多重集”的理论,即用神经网络参数化通用多重集函数。我们的下一个引理表明,求和聚合器可以代表多重集合的单射,事实上,是多重集上的通用函数。
引理 5. 定义如下:

该引理扩展了设置 (Zaheer et al., 2017) 从集合到多重集。深多重集和集合之间的一个重要区别是某些单射集合函数,例如均值聚合器,不是多重集函数。利用引理 5 中通用多重集函数的建模机制作为构建块,现在我们提出一种聚合方案,可以表示节点对和其邻居的多重集合上的通用函数,从而满足定理 3a 中的单射性条件。 我们的下一个推论在许多这样的聚合方案中提供了简单而具体的公式。
推论 6. 定义如下:
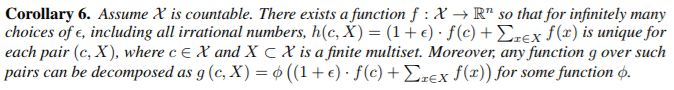
由于通用逼近定理(Hornik 等,1989; Hornik,1991),我们可以使用多层感知器(MLP)来推导和学习推论 6 中的 f 和φ,在实际应用中,我们用一个 MLP 对 f(k+1) ◦ φ (k) 进行建模,因为 MLP 可以表示函数的组成。在第一个迭代中,如果输入特征是一个热编码,那么在求和之前不需要 MLP,因为它们的求和是单射的。我们可以制作一个可学习的参数或固定的标量。然后,GIN 更新节点表征如下:
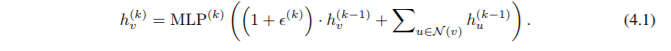
通常,可能存在许多其他强大的 GNNs。 虽然 GIN 很简单,但是它是最强大的 GNN 中的一个。读取不同部分的子树结构
图级读出(readout)的一个重要方面是,随着迭代次数的增加,对应于子树结构的节点表征变得更加精细和全局。足够数量的迭代是实现良好区分力的关键。 然而,特征的早期迭代有时可能更好地泛化。为了考虑所有的结构信息,GIN 从模型的所有深度 / 迭代使用信息。 我们通过类似于跳跃知识网络(JK-Nets)(Xu 等人,2018)的架构来实现这一点,其中在所有的迭代中我们使用连接后的图的表征向量替换了 Eq.2.4:

根据定理 3 和推论 6,如果 GIN 使用对来自相同迭代的所有节点特征求和来取代 Eq.4.2 中的 READOUT(在求和之前我们不需要额外的 MLP,原因与方程 4.1 相同),它可以推广 WL 测试和 WL 子树核。能力不强但仍然有趣的其他 GNNs
接下来我们研究不满足定理 3 中条件的 GNN,包括 GCN(Kipf&Welling,2017)和 GraphSAGE(Hamilton 等,2017a)。
我们对 Eq. 4.1 中聚合器的两个方面进行消融研究:(1)使用 1 层的感知器代替 MLP;(2)利用平均或最大池而不是求和。
令人惊讶的是我们观察到这些 GNN 变体被简单的图所迷惑,并且没有 WL 测试强大。 尽管如此,使用平均聚合器的模型像 GCN 在节点分类任务中还是表现良好。 为了更好地理解这一点,我们精确地描述了不同 GNN 变体能够和不能够捕获图的哪些内容,并讨论学习图的含义。1- 层的感知机并不充分
引理 5 中的函数 f 有助于将不同的多重集合映射到唯一的嵌入。它可以通过 MLP 通过通用逼近定理参数化(Hornik,1991)。尽管如此,许多现有的 GNN 使用 1- 层感知器σ°W 代替(Duvenaud 等人,2015; Kipf&Welling,2017; Zhang 等人,2018),线性映射后跟非线性激活函数,如 ReLU。 这种 1- 层映射是广义线性模型的例子(Nelder&Wedderburn,1972)。因此,我们对了解 1- 层感知器是否足以进行图学习非常感兴趣。引理 7 表明确实存在网络邻域(多重集合),具有 1- 层感知器的模型永远无法区分。
引理 7. 定义如下:
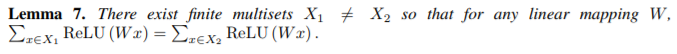
引理 7 证明的主要思想是 1 层感知器的行为很像线性映射,因此 GNN 层退化为简单地对邻域特征求和。我们的证据建立在线性映射中缺少偏差项的事实上。利用偏差项和足够大的输出维数,1- 层感知器可能能够区分不同的多重集。 尽管如此,与使用 MLP 的模型不同,1- 层感知器(即使具有偏置项)也不是多重集函数的通用逼近器。
因此,即使具有 1- 层感知器的 GNN 在某种程度上可以将不同的图嵌入到不同的位置,这种嵌入也可能不能充分地捕获结构相似性,并且对于简单的分类器(例如,线性分类器)来说可能难以拟合。 在第 7 节中,我们将凭经验看到具有 1- 层感知器的 GNN,当应用于图分类时,有时会严重欠拟合,并且在测试精度方面通常表现不及 MLP 的 GNN。混淆平均值和最大池的结构
如果我们将 h(X)=sum(f(x)) ,其中 x∈X,中的求和替换为 GCN 和 GraphSAGE 中的均值或最大池,会发生什么?平均和最大池聚合器仍然是定义良好的多重集函数,因为它们是置换不变的。但是,它们不是单射的。


图 2 根据三个聚合器的表示能力对其进行排序,图 3 说明了平均池和最大池聚合器对结构对无法区分。在这里,节点颜色表示不同的节点特征,我们假设 GNN 在将它们与中心节点组合之前先聚合邻居。
在图 3a 中,每个节点具有相同的特征 a,并且 f(a) 在所有节点上是相同的(对于任何函数 f)。当执行邻域聚合时,f(a) 上的均值或最大值仍为 f(a),并且通过归纳,我们总是在任何地方获得相同的节点表示。因此,均值和最大池聚合器无法捕获任何结构信息。相反,求和聚合器可以区分结构,因为 2·f(a) 和 3·f(a) 给出了不同的值。相同的参数可以应用于任何未标记的图。如果节点度不是常量值,则可以用作节点输入特征,原则上,均值可以覆盖求,但最大池不能。
图 3a 表明均值和最大值难以区分具有重复特征的节点的图。假设 h(color)(r 代表红色,g 代表绿色)表示由 f 转换后的节点特征。图 3b 显示蓝色节点附近的最大值产生 max(h(g),h(r)) 和 max(h(g),h(r),h(r)),这两个值折叠成相同的表示。因此,最大池无法区分它们。相比之下,求和聚合器仍然有效,因为 1/2*(h(g)+h(r)) 和 1/3*(h(g)+h(r)+h(r)) 通常是不等同的。同样地,在图 3c 中,平均值和最大值均为失败 1/2*(h(g)+h(r)) 和 1/4*(h(g)+h(g)+h(r)+h(r))。平均学习分布
为了描述平均聚合器可以区分多重集的类,考虑示例 X1 = (S, m) and X2 = (S, k · m),其中 X1 和 X2 具有相同的一组不同元素的集合,但 X2 包含 X1 的每个元素的 k 个副本。任何平均聚合器都将 X1 和 X2 映射到相同的嵌入,因为它只需要对单个元素的特征取平均值。因此,平均值可以捕获多重集中元素的分布(或者比例),而不是精确的多重集。
推论 8. 定义如下:

对于任务而言,如果图中的统计和分布信息比精确的结构更为重要,则平均聚合器可能表现良好。此外,当节点特征多样且很少重复时,平均聚合器与求和聚合器一样强大。这就可以解释为什么,尽管存在第 5.2 节中提到的一些限制,但带有平均聚合器的 GNN 对于节点分类任务还是有效,例如对文章主题进行分类和社区检测,其中节点特征丰富,并且邻域特征的分布为任务提供了一个强有力的信号。具有不同元素的最大池学习集
图 3 中的示例说明最大池认为具有相同的特征的多个节点仅为一个节点(即,将多重集合视为一个集合)。 最大池不捕获确切的结构和分布。 但是,它可能适用于某些识别任务,这些任务中识别元素或“骨架”更重要,而不是区分确切的结构或分布。( 齐等人.2017)凭经验表明,最大池聚合器学习识别 3D 点云的骨架,并且它对噪声和异常值具有鲁棒性。 为了完整起见,下一个推论显示最大池聚合器捕获多重集的基础集。
推论 9. 定义如下

实验设置
我们评估和比较 GIN 和不太强大的 GNN 变体的训练和测试性能。数据集
我们使用 9 个图分类基准:4 个生物信息学数据集(MUTAG,PTC,NCI1,PROTEINS)和 5 个社交网络数据集(COLLAB,IMDB-BINARY,IMDB-MULTI,REDDIT-BINARY 和 REDDIT-MULTI5K)(Yanardag&Vishwanathan,2015)。
在生物信息图中,节点具有分类输入特征 ; 在社交网络中,它们没有任何特征。 对于 REDDIT 数据集,我们将所有节点特征向量设置为相同(因此,这里的特征是无信息的); 对于其他社交图,我们使用节点度的独热编码。模型和配置
我们评估 GIN(方程 4.1 和 4.2)和不太强大的 GNN 变体。在 GIN 框架下,我们考虑两种变体:1)通过梯度下降,学习方程式 4.1 中的ε的 GIN,我们称之为 GIN-ε;(2)更简单(稍微不那么强大)的 GIN,其中ε在方程式中 4.1 固定为 0,我们称之为 GIN-0。
正如我们将要看到的,GIN-0 显示出强大的经验性能:GIN-0 不仅与 GIN-ε一样拟合的训练数据好,它还表现出良好的泛化性,在测试精度方面略微但始终优于 GIN-ε。对于能力较弱的 GNN 变体,我们考虑使用 mean 或 max-pooling 替换 GIN-0 聚合中的求和的架构,或者用 1- 层感知器替换 MLP,即线性映射后面接 ReLU。在图 4 和表 1 中,模型由它使用的聚合器 / 感知器命名。我们对 GIN 和所有 GNN 变体应用相同的图级 readout(公式 4.2 中的 READOUT),特别是生物信息学数据集的求和 readout 以及由于更好的测试性能而在社交数据集上的平均 readout。
以下(Yanardag&Vishwanathan,2015; Niepert 等,2016),我们使用 LIB-SVM 进行 10 倍交叉验证(Chang&Lin,2011)。我们公布了通过 cv 进行的 10- 交叉验证 validate 集的准确度的平均值和标准差。对于所有的配置,应用 5 个 GNN 层(包括输入层),并且所有 MLP 具有 2 个层。BN 标准化(Ioffe&Szegedy,2015)应用于每个隐藏层。我们使用 Adam 优化器(Kingma&Ba,2015),初始学习率为 0.01,并且每 50 个 epochs 将学习率衰减 0.5。我们针对每个数据集调优的超参数是:(1)生物信息图的 hidden units 的大小∈{16,32}和社交图的大小为 64; (2)批量大小(batch size)∈{32,128}; (3)在 dense 层后,dropout 率∈{0,0.5}(Srivastava 等,2014); (4)epochs 的数量。基准线
我们将上面的 GNN 与一些性能最佳的图分类基线进行了比较:
(1)WL 子树内核(Shervashidze 等,2011),其中使用了 C-SVM(Chang&Lin,2011) 作为分类器。 我们调优的超参数是 SVM 中的 C 和 WL 迭代的数量∈{1,2,…,6};
(2)性能最佳的深度学习架构扩散 – 卷积神经网络(DCNN)(Atwood&Towsley,2016)、PATCHY-SAN(Niepert 等,2016)和 Deep Graph CNN(DGCNN)(Zhang et al.,2018);
(3)Anonymous Walk Embeddings(AWL)(Ivanov&Burnaev,2018)。
对于深度学习方法和 AWL,我们报告了原始论文中报告的准确性。


实验结果训练集性能
通过比较它们的训练精度,我们验证了 GNNs 的强大表征能力的理论分析。图 4 显示了具有相同超参数设置的 GIN 和不太强大的 GNN 变种的训练曲线。
首先,理论上最强大的 GNN,即 GIN-ε (Sum–MLP),和 GIN-0 能够完美拟合所有的训练数据。在我们的实验中,与在 GIN-0 中把ε固定为 0 相比,在拟合训练数据时,用 GIN-ε显式学习ε没有任何收益。相比之下,在许多数据集中,使用平均 / 最大池或 1- 层感知机的 GNN 变体严重欠拟合。特别是,训练精度模式与我们通过模型的表征能力进行的排名一致:具有 MLP 的 GNN 变体比具有 1- 层感知器的 GNN 变体具有更高的训练精度,具有求和聚合器的 GNN 比具有平均和最大池聚合器的 GNN 更好的拟合训练集。
然而,在我们的数据集上,GNN 的训练精度从未超过 WL 子树内核的精度,后者具有与 WL 测试相同的区分能力。例如,在 IMDBBINARY 上,没有一个模型能够完全拟合训练集,而且 GNN 最多能达到与 wl 内核相同的训练精度。此模式与我们的结果一致,即 WL 测试为基于聚合的 GNN 的表示能力提供了一个上限。我们的理论结果集中在表征能力上,还没有考虑到优化(例如局部极小)。尽管如此,实验结果与我们的理论非常吻合。测试集性能
接下来,我们比较测试集精度。虽然我们的理论结果并不能直接说明 GNN 的泛化能力,但有理由期待具有较强表达力的 GNN 能够准确地捕获感兴趣的图结构,因此泛化能力非常好。表 1 比较了 GINs(SUM-MLP)、其他 GNN 变种以及最佳基准线的测试精度。结 论
在本文中,我们建立了 GNN 表达能力推理的理论基础,并对流行的 GNN 变体的表达能力进行了严格的论证。在此过程中,我们还在邻域聚合框架下设计了一个可以证明是最强大的 GNN。未来工作的一个有趣方向是超越邻域聚合(或消息传递)框架,以追求更强大的图学习架构。理解和改进 GNN 的泛化性质也是很有意思的。