转自 AI科技大本营
新一代人工智能带来的挑战
现在以深度神经网络为代表的AI带动了新一轮人工智能的发展。但是,在这个发展后面,也有很多新的挑战和隐忧。在自动驾驶领域,有特斯拉出现车祸,在目前利用一些方法来进行深度伪造,嘴边拿一个视频过来就可以把你自己说的话换成名人的头像,比如这张图,让奥巴马说一段其他名人说的话。我记得前段时间国内有批量换脸的应用,但是很快下架了。所以,深度伪造带来的潜在社会危害是非常巨大的。

还有人工智能的公平性问题,这在国内外许多AI应用里面都有提到,比如不同肤色、不同人种用AI进行智能司法判决的时候,包括在找工作的时候AI进行自动简历筛查,包括在银行进行贷款发放的时候等等,如果算法在数据上面的处理不够均衡,很有可能算法所做出的最终判断就是有偏差的,从伦理道德来说就会带来很严重的社会问题。
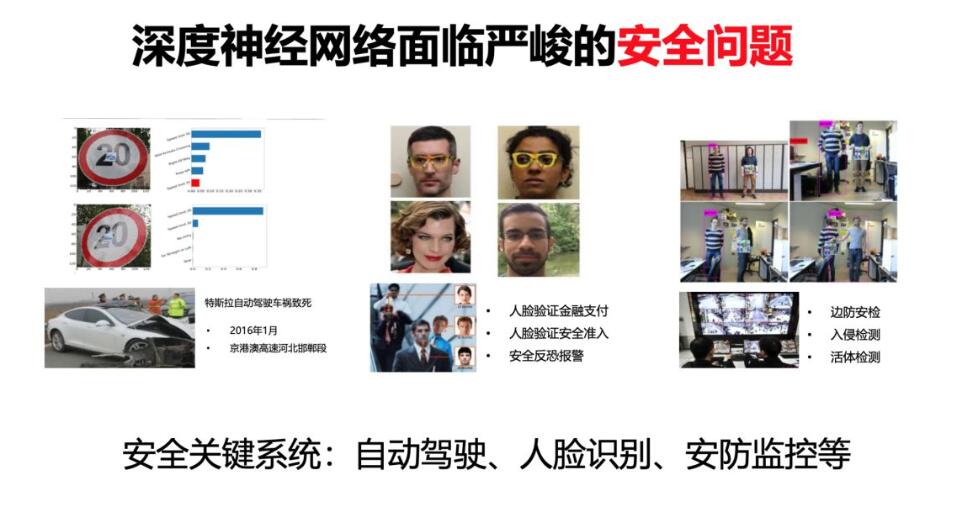
我今天重点讲的是关于深度神经网络本身的安全问题。虽然在座很多开发者和同学都用过深度神经网络,但是你会发现,虽然深度神经网络在相当数据情况下解决很多问题,比传统方法的效率和效果都要好,但是安全性确实是深度神经网络目前最需要解决的问题。如果你把这样不安全的神经网络应用在自动驾驶、应用在人脸识别、应用在安防监控这些领域里面,带来的危害是现实的。
我们这里可以总结一下在AI治理方面或者伦理原则方面,以获取人的信任为主要核心,覆盖方向主要是四个,一个是Security(安全),二是Transparency(透明度),这个算法不是黑箱,让人理解深度神经网络的运行、推理过程和训练过程。第三是Privacy(隐私)。第四是Fairness(公平性)。
这些原则无论是学术界还是工业界,都在开展很多研究。因为围绕着前面这四个原则,去探讨法律、道德甚至哲学层面,可以永远探讨下去,因为这是我们人类社会对终极正义追求的一种表现。
AI治理技术
目前来说,我个人觉得最重要的是怎么样把与人为善的AI的根本原则能够落地,能够和现有技术手段进行有机结合。
比如,在透明化方面正在做可解释性的工作,包括对AI的推理过程翻译成自然语言,包括把一个复杂的黑箱式的深度神经网络能不能等价成一个简化的代理网络,比如决策树、贝叶斯图。还有各种深度神经网络的可视化工作,把神经元推理过程中不同输入情况下激活的状态以可视化的方式展现出来

另外一个是溯源,因为AI模型和应用是不断连续的过程,从它产生数据到中间数据不断训练出来的模型,以及训练中产生的方法,在软件工程中,都可以用分阶段版本的形式刻画出来,然后把演化过程或数据给表达出来。当出现问题的时候,就可以分阶段地进行判断、审计、健全等等,通过这样的方式最终确定AI模型在一定文化或者事故情况下的权利划分。
还有两个针对AI治理的技术,一个是测试技术,一个是形式化验证技术。
在软件工程里,对软件的形式化验证有很多年的研究,主要是利用计算机科学里的形式化方法,也就是梳理逻辑和离散数学里的形式方法,对程序的建立、数学模型和建模情况下程序的行为、属性所需要的满足性质进行验证。
目前,学术界还没有得到一个非常短时间内可以覆盖很大规模神经网络的形式化工具,但是在最近几年,一些初步研究探索已经在开始了,至少可以对部分情况用形式化的方法:对神经元在不同输入里的上下边界进行数值的刻画。神经元最大的问题是有扰动的情况下会产生严重偏差,这会导致很严重的误判。所以未来可以期待的是,至少在一定范围里,特别是自动驾驶,肯定会出现比较严格的面向神经网络的形式化方法,以保证将来训练出来的关键系统的模型的可能性。
最后一个是测试技术,我们知道软件里面测试很多年了,方法也很成熟。对于神经网的测试,没有把它作为工程法的方法来对待,大家在不平常当中对学习训练的测试是用测试集来训练它的acc、auc等性能,但是对它在扰动情况下出现的各种错误行为,过去这种测试是比较少的。对神经网本身的一些覆盖测试、黑盒测试研究等等也是刚开始。

综合这些技术,在目前这种AI大潮情况下,能够把人工智能模型的开发和运维周期有效结合起来,无论是从任务的提出到模型训练数据的收集,到训练过程,到对模型的测试和评价过程,以及到最后的模型应用,我们都可以不断地加入刚才提到的这些治理要求,比如刚才讲的公平的要求、质量的要求等等。通过工具嵌入到开发周期当中,能够使得在每一个阶段都能使模型数据、模型本身的实现能达到我们的伦理期待,这是将来很多人都会不断推进和做的一件事情。
目前,在测试方面国家虽然有很多宏观政策,要求我们人工智能安全、可靠、可控地发展,但是目前还没有对于机器学习算法的统一测试方法、标准规范,这都是急需要推进的事情。在国外,包括ISO、美国标准局和加拿大等等陆续出台了一些法规,很多都是含糊的原则性措辞,可以想见,在这个领域是大有可为的。
我们想到将来的AI产品、算法和模型如果要大规模推广,不只是它的功能,安全、可靠这些东西都要做测试,如果达不到测试标准,那它根本没有办法得到国家有关部门的授权,能够真正在市场中推广。我相信将来肯定会出现这么一种局面,所以所有的重要领域的AI算法产品,你要真正部署应用的时候,必须要经过严格的测试和认证。
国内外研究现状

这几年这个领域的研究非常活跃,特别是从软件工程角度和对AI模型自身角度的研究,特别是哥伦比亚大学做的工具、自动驾驶做的deep test工具,包括IBM、谷歌、清华、百度等等都有相应的工具出台。

对于这些研究主要集中在对神经网的对抗样本研究,也就是说,目前运用GAN网络,在正常情况下,通过加入人眼无法辩识的信号干扰,使得AI模型产生完全不期望的结果。比如一个熊猫,你加一些噪音进去,认成猴子或者猩猩,一个香蕉加了干扰可能认为是矿卷水瓶子。
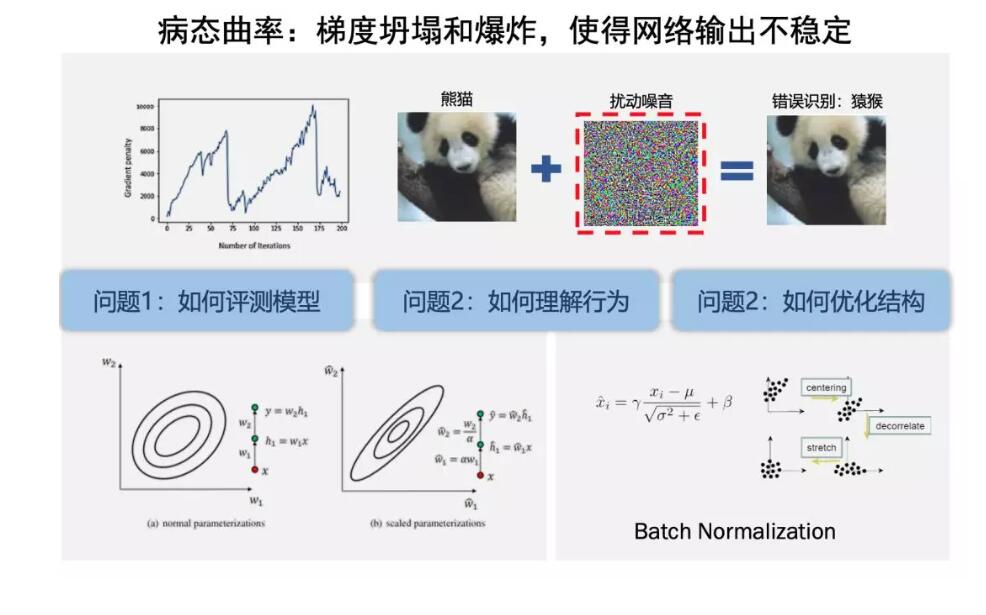
大量的数据和大规模网络在训练的时候,我们知道深度神经网络都是用算法迭代式的进行优化,往往只找到局部的最优点,不能找到全局的,所以优化过程中最优化的曲率和梯度坍塌、爆炸都是常见的问题。通过反复训练,使模型性能提高了百分之几,但是模型的安全性是极无法得到保障的,是极不稳定的。
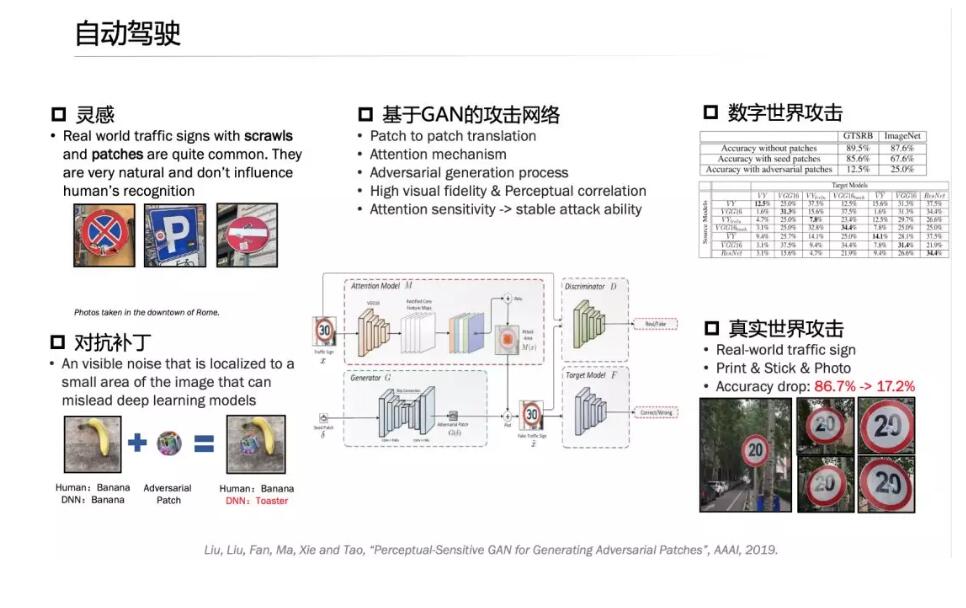
在这里,我们做了一系列工作,包括在路牌上贴一些小的patch,根据算法来生成,实际上是加了一些噪音,最后使得自动驾驶的算法在进行停车、通行、限速方面,完全不一样,比如指定限速20迈,通过加上标签,一下提升到80迈,自动驾驶的车辆过去的时候会产生严重的误判,就会产生问题,这都是用GAN的算法生成, 需要充分考虑到场景。
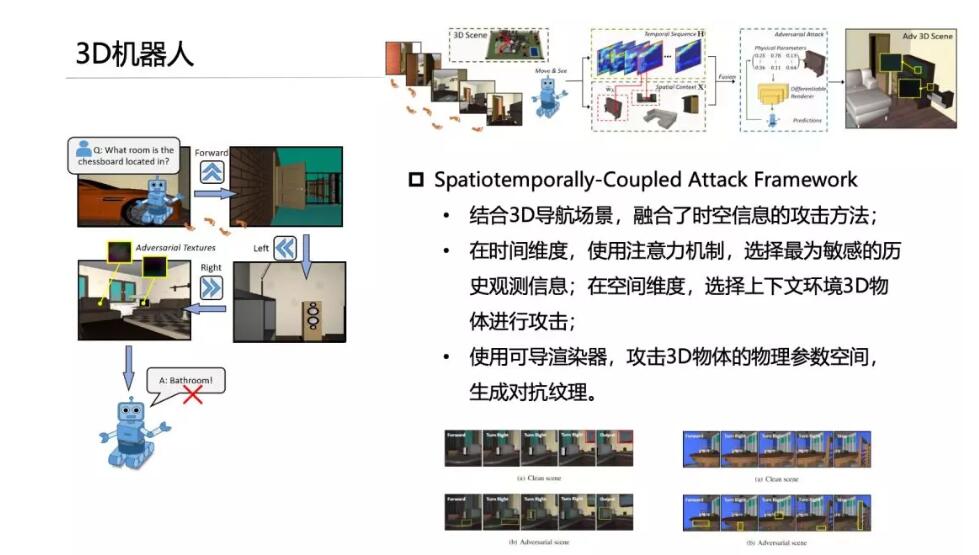
另外,我们把这样算法用在机器人导航识别当中,比如三维导航场景当中机器人需要识别物体对象是什么,通过三维场景中增加一些扰动信号,可以使得典型的机器人算法发生根本性误判。
这里也有一个展示,跟大家网上购物有关系,比如京东或者其他购物APP可以对物体进行拍照,可以在网上商城找到相应的商品列表。比如在方便面上打一个这样的patch或者在矿泉水瓶上打一个patch,最后认出的商品是五花八门的,完全不是你想要的情况。

模型测试
刚才PPT显示了在场景里面增加对抗的patch,能够使得机器学习算法完全失效的情况。我们通过什么方法能够更好地加固和优化我们的算法,以避免产生这样的误判、提升系统的稳定性和鲁棒性?
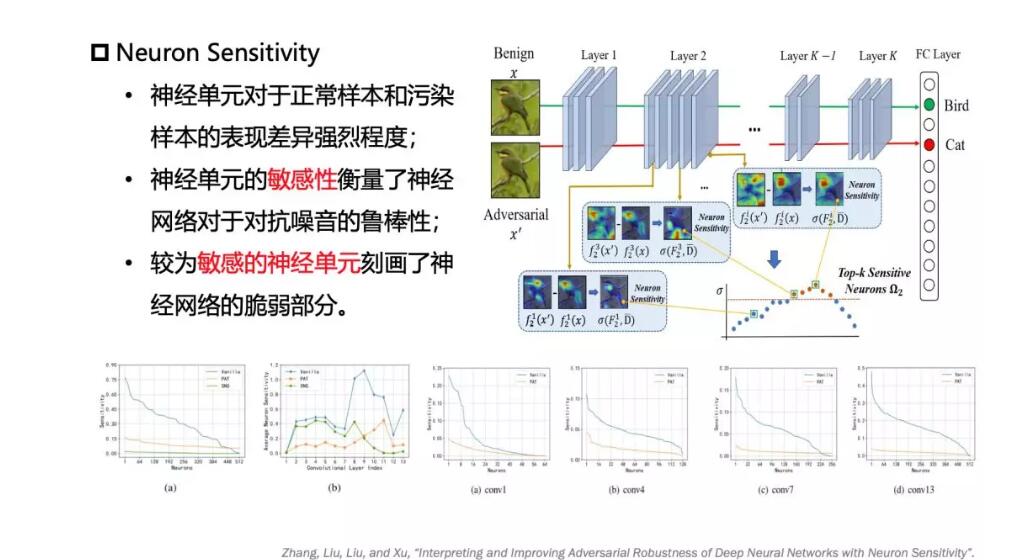
我们做的工作,对于神经元的敏感性进行刻画。这个敏感性定义是说,你对神经网络进行对抗性样本输入的时候,很明显的观察到,并不是所有神经元都是敏感的,并不是所有东西都明显的产生比较剧烈的反应或者输出激活的状态下,所以你可以标出敏感度最高的神经元,围绕着神经元每一层输出的地方,可以加入自适应的调节机制,来弱化这个过度敏感的神经元对整个神经网络判别过程的影响。我们这里做了一些可视化的工作以及对于敏感性增强的一些工作。
模型理解
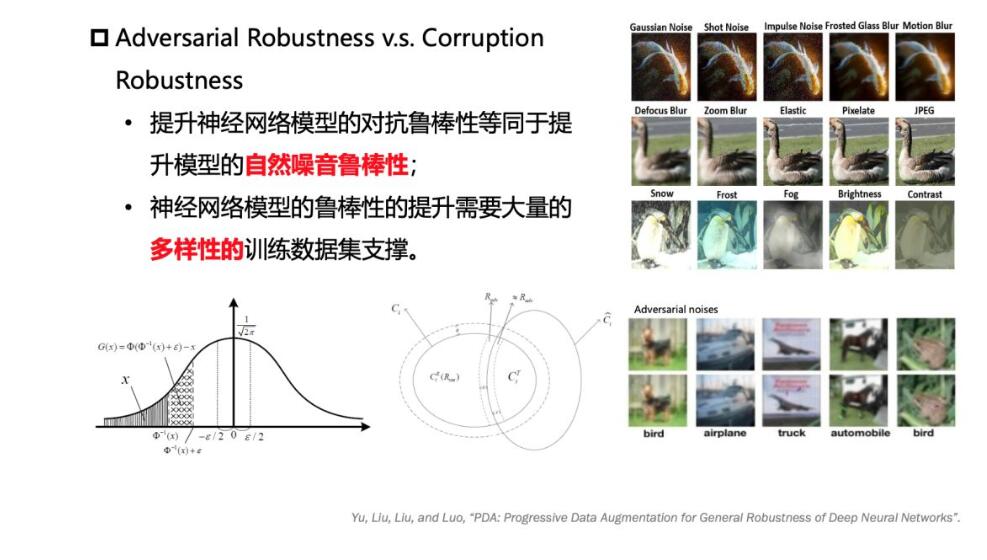
另外,对于模型不同信号的噪音,包括自然噪音和对抗样本生成的噪音,把相关性进行分析比较。在自然噪音情况下,比如加雪花、变形等等,和对抗样本生成的人工扰动具有一定的相似性,这就说明鲁棒性问题是模型本身的结构和模型的参数训练问题造成的。要解决它,除了在结构和参数的加固、优化外,在训练过程中多样性的训练数据也是很重要的。
这里组织了一个神经网可解释的专刊来推动对这方面的工作。这里是对模型量化进行的一些工作,特别是对量化参数加入一些线性网络模块,加在每一层现行权重输出的地方,能够使得权重在一个比较稳定的范围。

另外,我们把对抗样本加入到神经网的反向训练BP过程当中,通过这样的方式,可以有效地提升训练出来的神经网对抗的鲁棒性和对自然噪声的鲁棒性。
模型优化

这是刚才提到的对敏感性神经网怎么通过算法的方式进行有效地加固。

标准制定
目前,基于这一系列的工作,我们已经在这方面国家标准的制定方面进行了一些探讨,特别是在去年年底和今年年初的时候,中国电子工业化技术协会下推动了一项团标,专门是用来对机器学习算法的鲁棒性怎么进行度量,像最差的决策边界、噪音敏感度、神经元敏感度,把这些都纳入到团标当中,目前在把这个团标向国家标准立项方向进行推进。
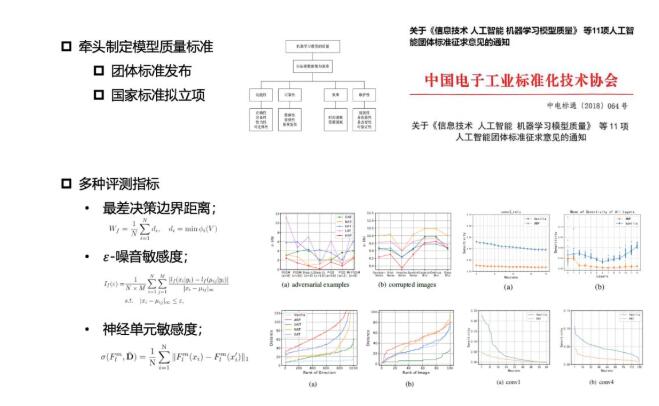
另外,我们跟工信部门合作,把刚才这些算法纳入到工信部门接绑行动的标准化评价评测平台的研制当中,构建相应的数据模型和资源库,同时引进模型的数据检测和模型评测的方法等等
平台建设

整个AI的运维管理,目前一般来说在下面需要一个云的环境。今天我们讲了各种开发工具,包括数据标注、主动学习、知识图谱的工具,特别强调了安全验证工具等等,这些都可以作为微服务来进行有效地串接在一起。在这上面,可以从数据的收集、整理、训练到模型部署、运维的整个流程来进行打通。

如果我们比较一下目前在软件工程CI/CD领域持续集成、持续部署流程和深度学习模型,这样的流程之间有一定的相似性。软件的CI/CD流程,软件要从代码库里面通过编译进行流程管理,引入一些工具对代码质量进行评测,然后放在Google Net或者其他云上面。我们对AI模型也是这样,需要选结构、设计和调优部署。目前大部分厂商对于设计调优和部署有相当多的工具支持,但是对图片中的这一块对评价测试和加固优化工作的开源工具相对比较少。这需要国内、国外大力开发研究和推进的。

这是我们研究的测试平台原型,和一般的开发流程差不多。

这是开发目前的基本界面,在这个界面大家可以提交自己的模型,我们通过生成的不同测试样本对抗噪音和自然噪音,对算法的性能、安全性、可靠性进行评测,进一步给出模型的改进建议。基于刚才的框架,还有很多后续的工作和工具可以继续来做。

根据刚才所说的这些,我们的计划是能够在理论研究和原型开发基础上,能够使平台更加成熟,计划在今年晚些时候能够纳入到我们的OpenI开源框架体系里,为AI持续健康的发展和治理做出努力。