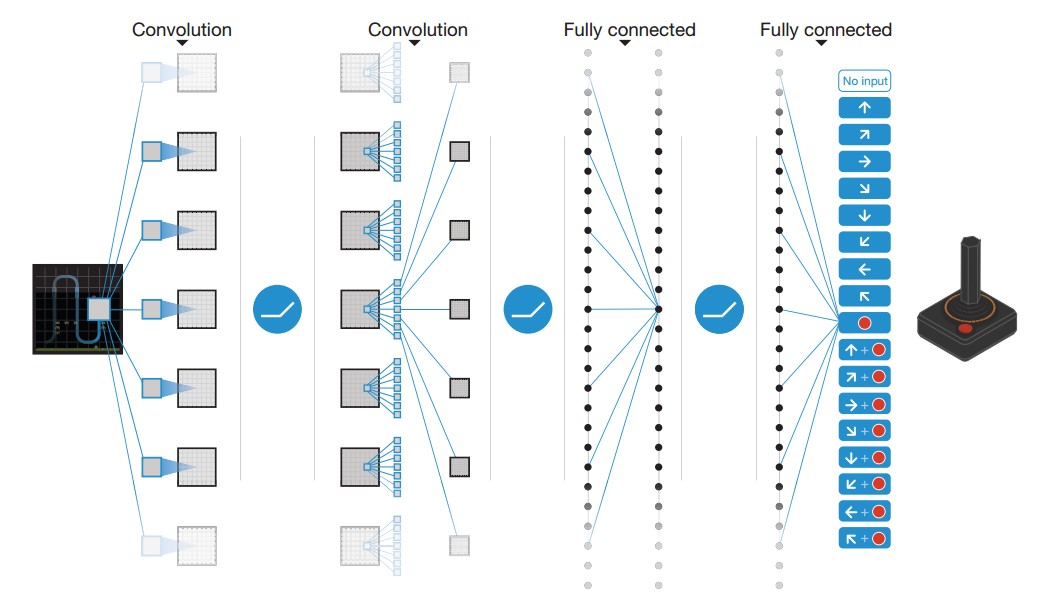
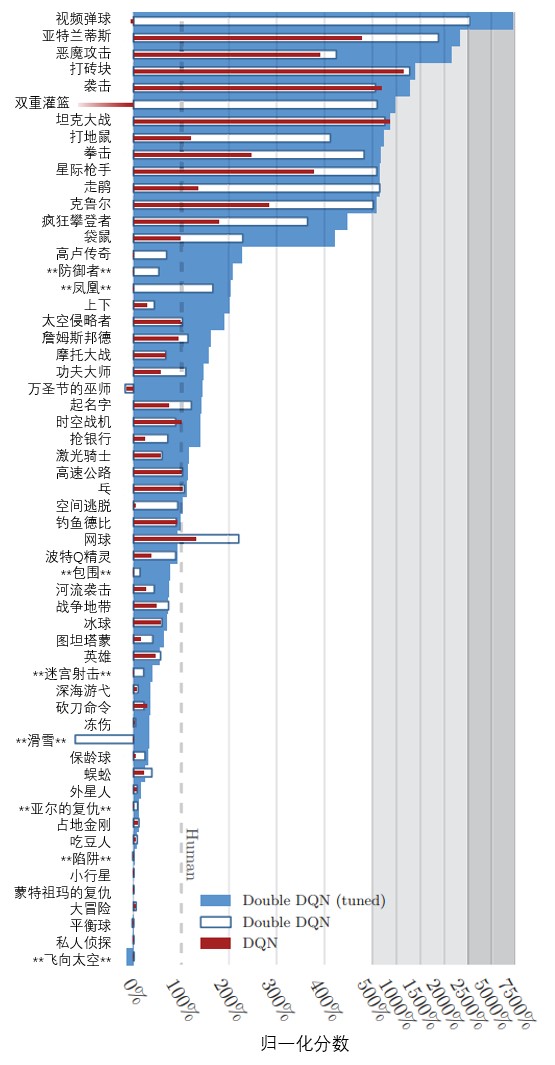
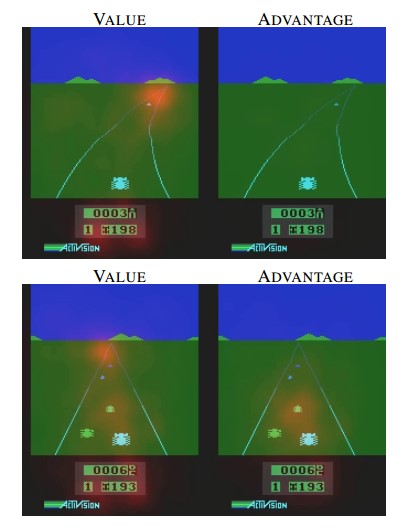
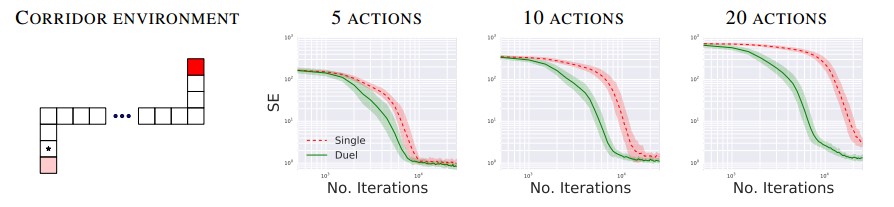
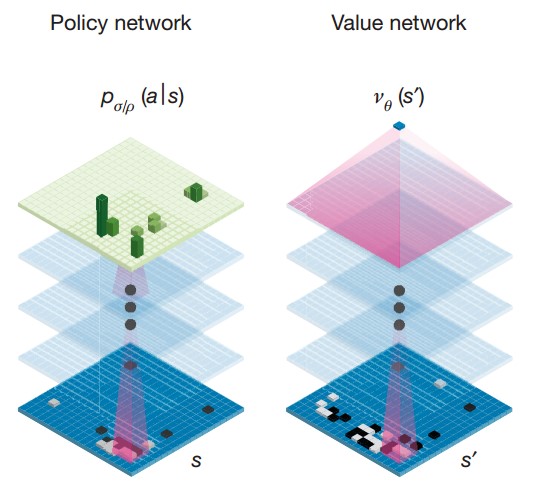
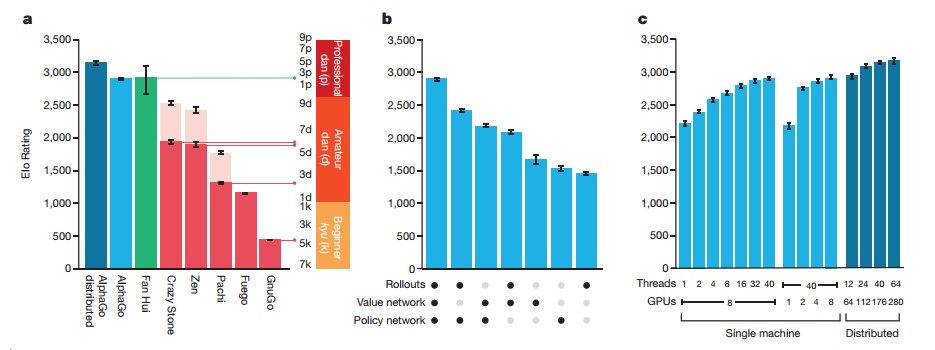
图14.1 DQN模型的网络结构(Mnih et al., 2015)图14.4 double DQN模型性能对比(Hasselt et al., 2016) 图14.6 Enduro游戏过程中的显著性分析(Wang et al., 2015)图14.8 DQN与Dueling Network DQN收敛性对比(Wang et al., 2015)图14.10 策略网络和价值网络(Silver et al., 2016)图14.14 AlphaGo Fan算法评估(Silver et al., 2016)图14.19 机器人开门实验(Levine et al., 2016)