转自 机器学习算法与自然语言处理
介绍
随着社交网络的快速发展,人们在平台上的表达方式变得越来越丰富,如通过图文和视频表达自己的情绪和观点。如何分析多模态数据(本文指声音,图像和文字,不涉及传感器数据)中的情感,是当前情感分析领域面临的机遇和挑战。
一方面,以往情感分析聚焦于单个模态。如文本情感分析着眼于分析,挖掘和推理文本中蕴含的情感。现在需要对多个模态的数据进行处理和分析,这给研究人员带来了更大的挑战。另一方面,多模态数据与单模态数据相比,包含了更多的信息,多个模态之间可以互相补充。例如,在识别这条推文是否为反讽,“今天天气真好!”。如果只从文本来看,不是反讽。而如果其附加一张阴天的图片,可能就是反讽。不同模态信息相互补充,可以帮助机器更好地理解情感。从人机交互角度出发,多模态情感分析可以使得机器在更加自然的情况下与人进行交互。机器可以基于图像中人的表情和手势,声音中的音调,和识别出的自然语言来理解用户情感,进而进行反馈。
综上来讲,多模态情感分析技术的发展源于实际生活的需求,人们以更加自然的方式表达情感,技术就应有能力进行智能的理解和分析。虽然多模态数据包含了更多的信息,但如何进行多模态数据的融合,使得利用多模态数据能够提升效果,而不是起了反作用。如何利用不同模态数据之间的对齐信息,建模不同模态数据之间关联,如人们听见“喵”就会想起猫。这些都是当前多模态情感分析领域感兴趣的问题。为了能够更好的介绍多模态情感分析领域的相关研究,本文梳理了目前多模态情感分析领域相关任务并总结了常用的数据集及对应的方法。
相关任务概览
本文通过不同模态组合(图文:文本+图片,视频:文本+图片+音频)来梳理相关的研究任务,对于文本+音频这种组合方式少有特意构建的相关数据集,一般通过对语音进行ASR或者使用文本+图片+音频中的文本+音频来构造数据集。对于文本+音频,语音方向的研究工作较多,所以本文暂未涉及。如表1所示,面向图文的情感分析任务有面向图文的情感分类任务,面向图文的方面级情感分类任务和面向图文的反讽识别任务。面向视频的情感分析任务有面向评论视频的情感分类任务,面向新闻视频的情感分类任务,面向对话视频的情感分类任务和面向对话视频的反讽识别任务。本文总结了与任务对应的相关数据集及方法,具体内容见第三部分。
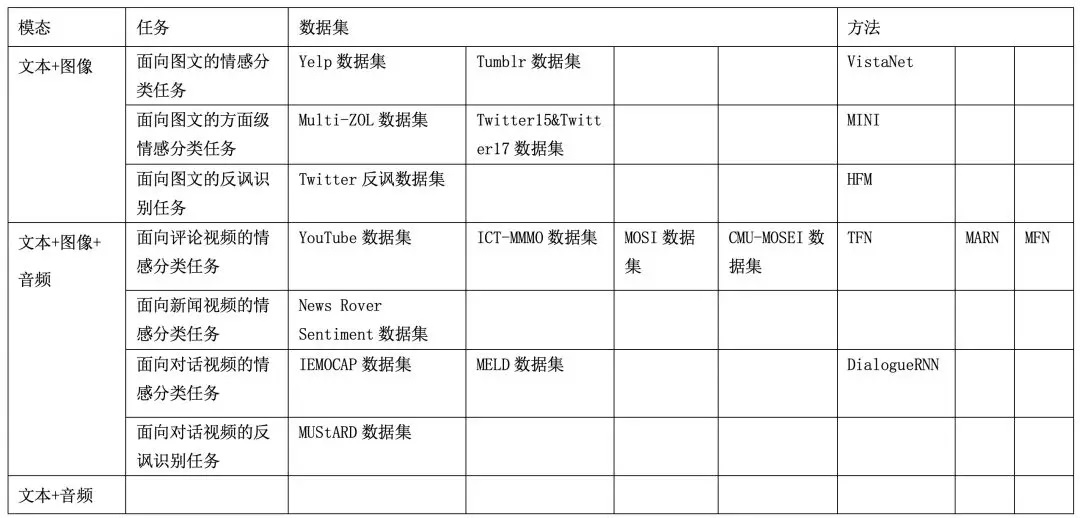
数据集和方法
本文总结了13个公开数据集,其中包括8个视频数据集和5个图文数据集。本文还总结了与面向图文的情感分类任务,面向图文的方面级情感分类任务,面向图文的反讽识别任务,面向评论视频的情感分类任务和面向对话视频的情感分类任务五个任务对应的相关研究方法。
面向图文的情感分类任务
数据集
Yelp数据集来自Yelp.com评论网站,收集的是波士顿,芝加哥,洛杉矶,纽约,旧金山五个城市关于餐厅和食品的Yelp上的评论。一共有44305条评论,244569张图片(每条评论的图片有多张),平均每条评论有13个句子,230个单词。数据集的情感标注是对每条评论的情感倾向打1,2,3,4,5五个分值。
继续阅读