学术论文是发布自己或团队最新研究进展正式且最快捷的途径,也是和同行交流想法最方便、高效的方式。当同行评议(Peer review)作为学术成果正式发布的必经之路已运行200余年[1]时,用正确的姿势进行review rebuttal便成为提高论文录用机率甚至扭转乾坤的最后一搏。本文从“What is peer review?”、“How to rebuttal?”及“Does rebuttal matter?”三部分来聊聊学术论文(主要针对人工智能领域会议和期刊)rebuttal的那些事。
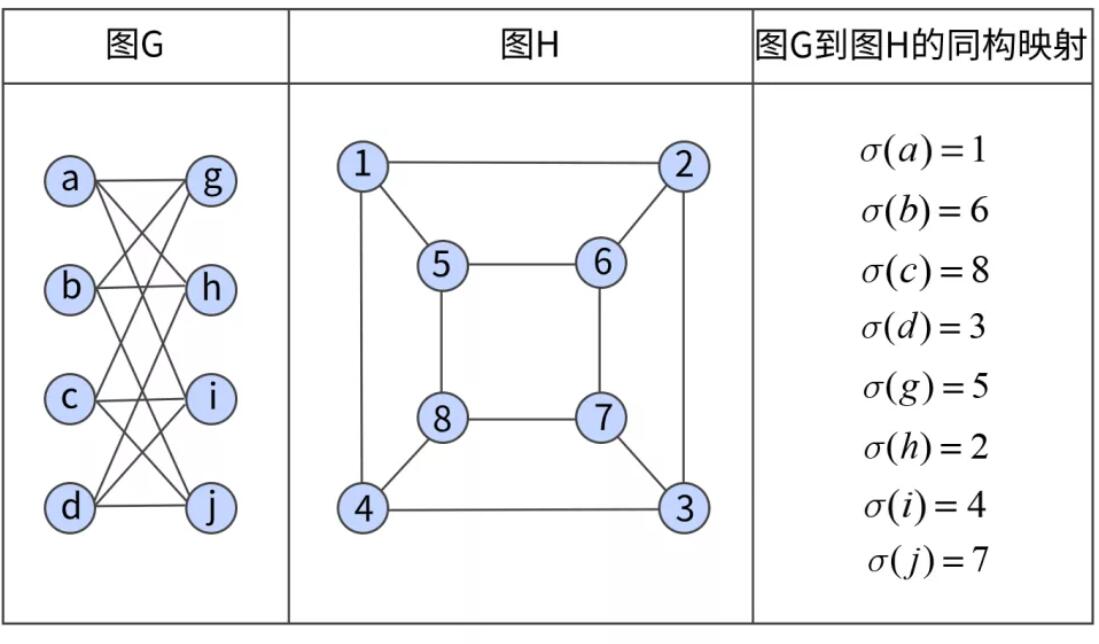
当前 GNN 研究的第一个热点在于其相关能力的理论化研究。在 “How Powerful are Graph Neural Networks?” 和 “On the equivalence between graph isomorphism testing and function approximation with GNNs” 中,都对 GNN 在图同构问题上的表现进行了探讨。图同构问题是辨别给定的两个图是否一致,同构图如下图所示。这个问题考验了算法对图数据结构的辨别能力,这两篇文章都证明了 GNN 模型具有出色的结构学习能力。图中天然包含了关系,因此许多 GNN 相关的工作就建立在对给定系统进行推理学习的研究上,在这些研究中,“Can graph neural networks help logic reasoning? ” 和 “The Logical Expressiveness of Graph Neural Networks” 论证了 GNN 在逻辑推理上的优秀表现。“All We Have is Low-Pass Filters ” 从低通滤波的层面解释了 GNN 的有效性。这些原理解读,有助于我们对 GNN 的特色专长建立一种更加清晰的认识。