转自 机器之心
该项目是对基于深度学习的自然语言处理(NLP)的概述,包括用来解决不同 NLP 任务和应用的深度学习模型(如循环神经网络、卷积神经网络和强化学习)的理论介绍和实现细节,以及对 NLP 任务(机器翻译、问答和对话系统)当前最优结果的总结。
该项目的主要动机如下:
- 维护最新 NLP 研究学习资源,如当前最优结果、新概念和应用、新的基准数据集、代码/数据集发布等。
- 创建开放性资源,帮助指引研究者和对 NLP 感兴趣的人。
- 这是一个合作性项目,专家研究人员可以基于他们近期的研究和实验结果提出变更建议。
第一章:简介
自然语言处理(NLP)是指对人类语言进行自动分析和表示的计算技术,这种计算技术由一系列理论驱动。NLP 研究从打孔纸带和批处理的时代就开始发展,那时分析一个句子需要多达 7 分钟的时间。到了现在谷歌等的时代,数百万网页可以在不到一秒钟内处理完成。NLP 使计算机能够执行大量自然语言相关的任务,如句子结构解析、词性标注、机器翻译和对话系统等。
深度学习架构和算法为计算机视觉与传统模式识别领域带来了巨大进展。跟随这一趋势,现在的 NLP 研究越来越多地使用新的深度学习方法(见图 1)。之前数十年,用于解决 NLP 问题的机器学习方法一般都基于浅层模型(如 SVM 和 logistic 回归),这些模型都在非常高维和稀疏的特征(one-hot encoding)上训练得到。而近年来,基于稠密向量表征的神经网络在多种 NLP 任务上得到了不错结果。这一趋势取决了词嵌入和深度学习方法的成功。深度学习使多级自动特征表征学习成为可能。而基于传统机器学习的 NLP 系统严重依赖手动制作的特征,它们及其耗时,且通常并不完备。
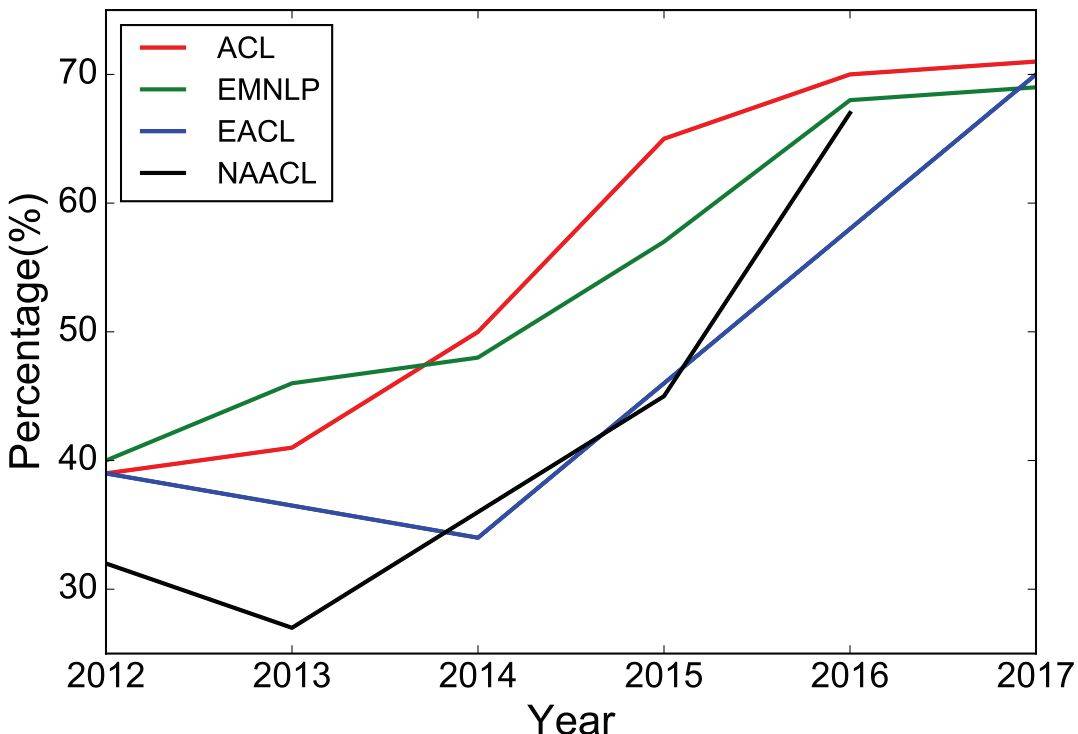
图 1:过去 6 年 ACL、EMNLP、EACL、NAACL 会议上深度学习论文的比例(长论文)。
Ronan Collobert 等人 2011 年的研究《Natural Language Processing (Almost) from Scratch》展示了在多个 NLP 任务上优于当时最优方法的简单深度学习框架,比如命名实体识别(NER)、语义角色标注(SRL)和词性标注。之后,研究人员提出了大量基于复杂深度学习的算法,用于解决有难度的 NLP 任务。本文综述了用于自然语言任务的主要深度学习模型和方法,如卷积神经网络、循环神经网络和递归神经网络。本文还讨论了记忆增强策略、注意力机制,以及如何使用无监督模型、强化学习方法和深度生成模型解决语言任务。
本文综述了 NLP 研究中最流行的深度学习方法,结构如下:第二章介绍分布式表征的概念,它们是复杂深度学习模型的基础;第 3、4、5 章讨论了流行的模型(如卷积、循环、递归神经网络)及其在不同 NLP 任务中的应用;第 6 章列举了强化学习在 NLP 中的近期应用,以及无监督句子表征学习的近期发展;第 7 章介绍了深度学习模型结合记忆模块这一近期趋势;第 8 章概述了多种深度学习方法在 NLP 任务标准数据集上的性能。机器之心选取了第 2、3、4、8 章进行重点介绍。
第二章:分布式表征
基于统计的 NLP 已经成为建模复杂自然语言任务的首要选择。然而在它刚兴起的时候,基于统计的 NLP 经常遭受到维度灾难,尤其是在学习语言模型的联合概率函数时。这为构建能在低维空间中学习分布式词表征的方法提供了动力,这种想法也就导致了词嵌入方法的诞生。
第一种在低维空间中学习密集型的分布式词表征是 Yoshua Bengio 等人在 2003 年提出的 A Neural Probabilistic Language Model,这是一种基于学习而对抗维度灾难的优美想法。
词嵌入
如下图 2 所示,分布式向量或词嵌入向量基本上遵循分布式假设,即具有相似语义的词倾向于具有相似的上下文词,因此这些词向量尝试捕获邻近词的特征。分布式词向量的主要优点在于它们能捕获单词之间的相似性,使用余弦相似性等度量方法评估词向量之间的相似性也是可能的。
词嵌入常用于深度学习中的第一个数据预处理阶段,一般我们可以在大型无标注文本语料库中最优化损失函数,从而获得预训练的词嵌入向量。例如基于上下文预测具体词(Mikolov et al., 2013b, a)的方法,它能学习包含了一般句法和语义的词向量。这些词嵌入方法目前已经被证明能高效捕捉上下文相似性,并且由于它们的维度非常小,因此在计算核心 NLP 任务是非常快速与高效的。
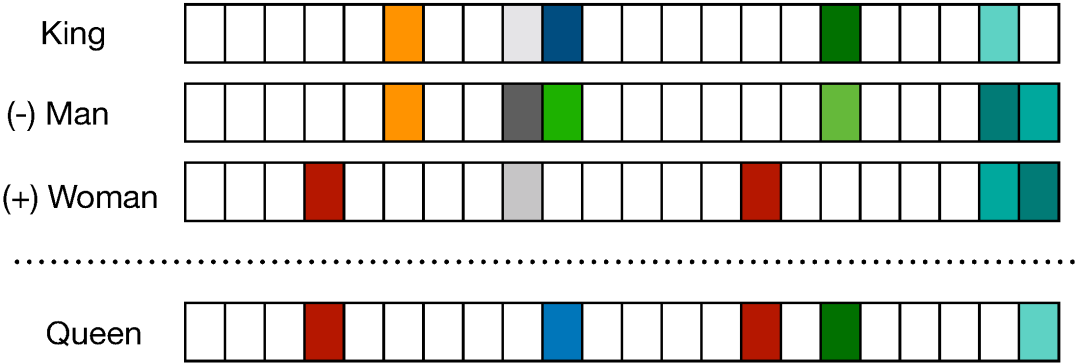
图 2:分布式词向量表征,其中每一个词向量只有 D 维,且远小于词汇量大小 V,即 D<<V。
多年以来,构建这种词嵌入向量的模型一般是浅层神经网络,并没有必要使用深层神经网络构建更好的词嵌入向量。不过基于深度学习的 NLP 模型常使用这些词嵌入表示短语甚至句子,这实际上是传统基于词统计模型和基于深度学习模型的主要差别。目前词嵌入已经是 NLP 任务的标配,大多数 NLP 任务的顶尖结果都需要借助它的能力。
本身词嵌入就能直接用于搜索近义词或者做词义的类推,而下游的情感分类、机器翻译、语言建模等任务都能使用词嵌入编码词层面的信息。最近比较流行的预训练语言模型其实也参考了词嵌入的想法,只不过预训练语言模型在词嵌入的基础上进一步能编码句子层面的语义信息。总的而言,词嵌入的广泛使用早已体现在众多文献中,它的重要性也得到一致的认可。
分布式表示(词嵌入)主要通过上下文或者词的「语境」来学习本身该如何表达。上个世纪 90 年代,就有一些研究(Elman, 1991)标志着分布式语义已经起步,后来的一些发展也都是对这些早期工作的修正。此外,这些早期研究还启发了隐狄利克雷分配等主题建模(Blei et al., 2003)方法和语言建模(Bengio et al., 2003)方法。
在 2003 年,Bengio 等人提出了一种神经语言模型,它可以学习单词的分布式表征。他们认为这些词表征一旦使用词序列的联合分布构建句子表征,那么就能构建指数级的语义近邻句。反过来,这种方法也能帮助词嵌入的泛化,因为未见过的句子现在可以通过近义词而得到足够多的信息。
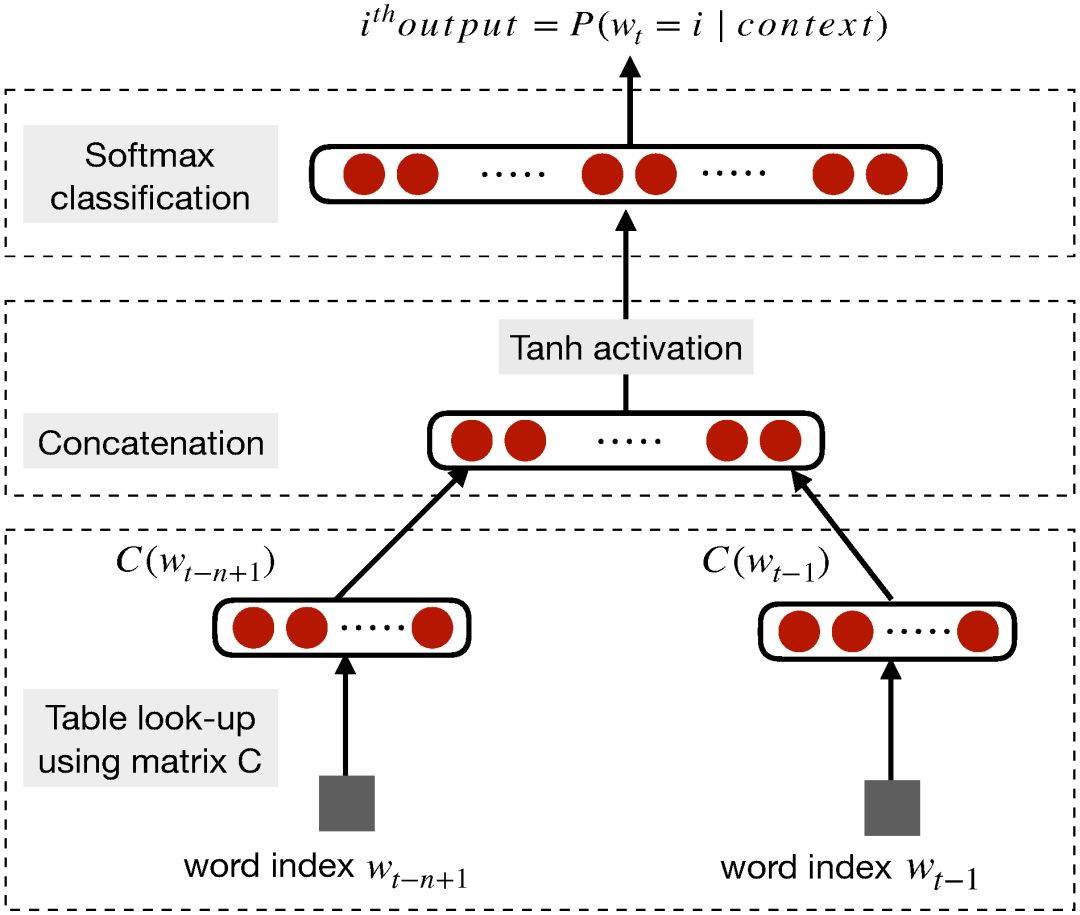
图 3:神经语言模型(图源:http://www.jmlr.org/papers/volume3/bengio03a/bengio03a.pdf)。
Collobert 和 Weston(2008) 展示了第一个能有效利用预训练词嵌入的研究工作,他们提出的神经网络架构构成了当前很多方法的基础。这一项研究工作还率先将词嵌入作为 NLP 任务的高效工具,不过词嵌入真正走向 NLP 主流还是 Mikolov 等人在 2013 年做出的研究《Distributed Representations of Words and Phrases and their Compositionality》。
Mikolov 等研究者在这篇论文中提出了连续词袋模型(CBOW)和 Skip-Gram 模型,这两种方法都能学习高质量的分布式词表征。此外,令这两种方法受到极大关注的是另一种附加属性:语义合成性,即两个词向量相加得到的结果是语义相加的词,例如「man」+「royal」=「king」。这种语义合成性的理论依据最近已经由 Gittens et al. (2017) 给出,他们表示只有保证某些特定的假设才能满足语义合成性,例如词需要在嵌入空间中处于均匀分布。
Pennington et al. (2014) 提出了另一个非常出名的词嵌入方法 GloVe,它基本上是一种基于词统计的模型。在有些情况下,CBOW 和 Skip-Gram 采用的交叉熵损失函数有劣势。因此 GloVe 采用了平方损失,它令词向量拟合预先基于整个数据集计算得到的全局统计信息,从而学习高效的词词表征。
一般 GloVe 模型会先对单词计数进行归一化,并通过对数平滑来最终得到词共现矩阵,这个词共现矩阵就表示全局的统计信息。这个矩阵随后可以通过矩阵分解得到低维的词表征,这一过程可以通过最小化重构损失来获得。下面将具体介绍目前仍然广泛使用的 CBOW 和 Skip-Gram 两种 Word2Vec 方法(Mikolov et al., 2013)。
Word2Vec
可以说 Mikolov 等人彻底变革了词嵌入,尤其是他们提出的 CBOW 和 Skip-Gram 模型。CBOW 会在给定上下文词的情况下计算目标词(或中心词)的条件概率,其中上下文词的选取范围通过窗口大小 k 决定。而 Skip-Gram 的做法正好与 CBOW 相反,它在给定目标词或中心词的情况下预测上下文词。一般上下文词都会以目标词为中心对称地分布在两边,且在窗口内的词与中心词的距离都相等。也就是说不能因为某个上下文词离中心词比较远,就认为它对中心词的作用比较弱。
在无监督的设定中,词嵌入的维度可以直接影响到预测的准确度。一般随着词嵌入维度的增加,预测的准确度也会增加,直到准确率收敛到某个点。一般这样的收敛点可以认为是最佳的词嵌入维度,因为它在不影响准确率的情况下最精简。通常情况下,我们使用的词嵌入维度可以是 128、256、300、500 等,相比于几十万的词汇库大小已经是很小的维度了。
下面我们可以考虑 CBOW 的简化版,上下文只考虑离中心词最近的一个单词,这基本上就是二元语言模型的翻版。
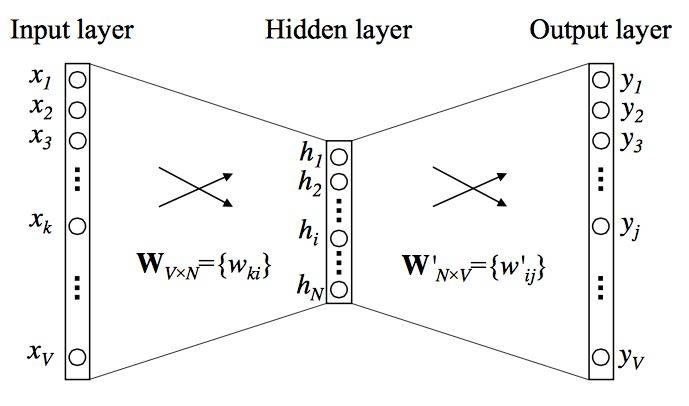
图 4:CBOW 模型。
如图 4 所示,CBOW 模型就是一个简单的全连接神经网络,它只有一个隐藏层。输入层是上下文词的 one-hot 向量,它有 V 个神经元(词汇量),而中间的隐藏层只有 N 个神经元,N 是要远远小于 V 的。最后的输出层是所有词上的一个 Softmax 函数。层级之间的权重矩阵分别是 V*N 阶的 W 和 N*V 阶的 W’,词汇表中的每一个词最终会表征为两个向量:v_c 和 v_w,它们分别对应上下文词表征和目标词表征。若输入的是词表中第 k 个词,那么我们有:
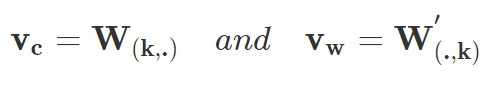
总体而言,在给定上下文词 c 作为输入的情况下,对于任意词 w_i 有:

参数 θ={V_w, V_c} 都是通过定义目标函数而学习到的,一般目标函数可以定义为对数似然函数,且通过计算以下梯度更新权重:
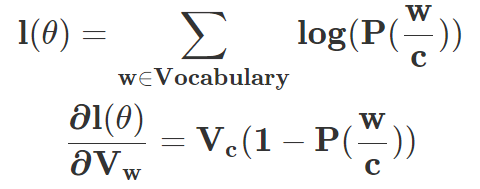
在更广泛的 CBOW 模型中,所有上下文词的 one-hot 向量都会同时作为输入,即:
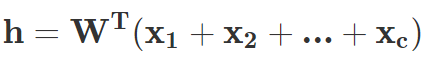
词嵌入的一个局限是它们无法表示短语(Mikolov et al., 2013),即两个词或多个词的组合并不表示对应的短语意义,例如「人民」+「大学」并不能组合成「人民大学」。Mikolov 提出的一种解决办法是基于词共现识别这些短语,并为它们单独地学一些词嵌入向量,而 Rie Johnson 等研究者在 15 年更是提出直接从无监督数据中学习 n-gram 词嵌入。
另一种局限性在于学习的词嵌入仅基于周围词的小窗口,有时候「good」和「bad」几乎有相同的词嵌入,这对于情感分析等下游任务很不友好。有时候这些相似的词嵌入有正好相反的情感,这对于需要区别情感的下游任务简直是个灾难,它甚至比用 One-hot 向量的表征方法还要有更差的性能。Duyu Tang(2014)等人通过提出特定情感词嵌入(SSWE)来解决这个问题,他们在学习嵌入时将损失函数中的监督情感纳入其中。
一个比较重要的观点是,词嵌入应该高度依赖于他们要使用的领域。Labutov 和 Lipson(2013) 提出了一种用于特定任务的词嵌入,他们会重新训练词嵌入,因此将词嵌入与将要进行的下游任务相匹配,不过这种方法对计算力的需求比较大。而 Mikolov 等人尝试使用负采样的方法来解决这个问题,负采样仅仅只是基于频率对负样本进行采样,这个过程直接在训练中进行。
此外,传统的词嵌入算法为每个词分配不同的向量,这使得其不能解释多义词。在最近的一项工作中,Upadhyay 等人 (2017) 提出了一种新方法来解决这个问题,他们利用多语平行数据来学习多语义词嵌入。例如英语的「bank」在翻译到法语时有两种不同的词:banc 和 banque,它们分别表示金融和地理意义,而多语言的分布信息能帮助词嵌入解决一词多义的问题。
下表 1 提供了用于创建词嵌入的现有框架,它们都可以训练词嵌入并进一步与深度学习模型相结合:
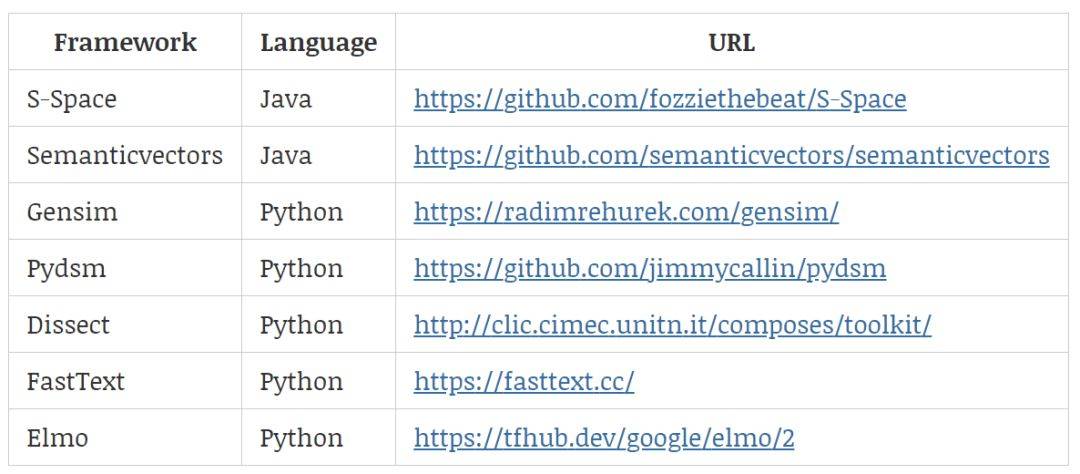
说到这里,小编不得不宣传一波我们的小项目,我们主要使用维基的中文语料训练了一个中文词嵌入,并提供了 Skip-Gram 和 GloVe 两种模型的训练方法。读者可以简单地使用我们已训练的词嵌入,或者根据我们提供的 Jupyter Notebook 教程学习如何训练词嵌入。简单而言,训练主要可以分为 5 个步骤,即下载维基中文语料、将繁体转化为简体、采用结巴分词、预处理并构建数据集、开始训练。
当然我们放在 Colab 的示例代码只是训练部分维基语料,但也能做出了较为合理的中文词嵌入。
项目地址:https://github.com/HoratioJSY/cn-words
第三章:卷积神经网络
随着词嵌入的流行及其在分布式空间中展现出的强大表征能力,我们需要一种高效的特征函数,以从词序列或 n-grams 中抽取高级语义信息。随后这些抽象的语义信息能用于许多 NLP 任务,如情感分析、自动摘要、机器翻译和问答系统等。卷积神经网络(CNN)因为其在计算机视觉中的有效性而被引入到自然语言处理中,实践证明它也非常适合序列建模。
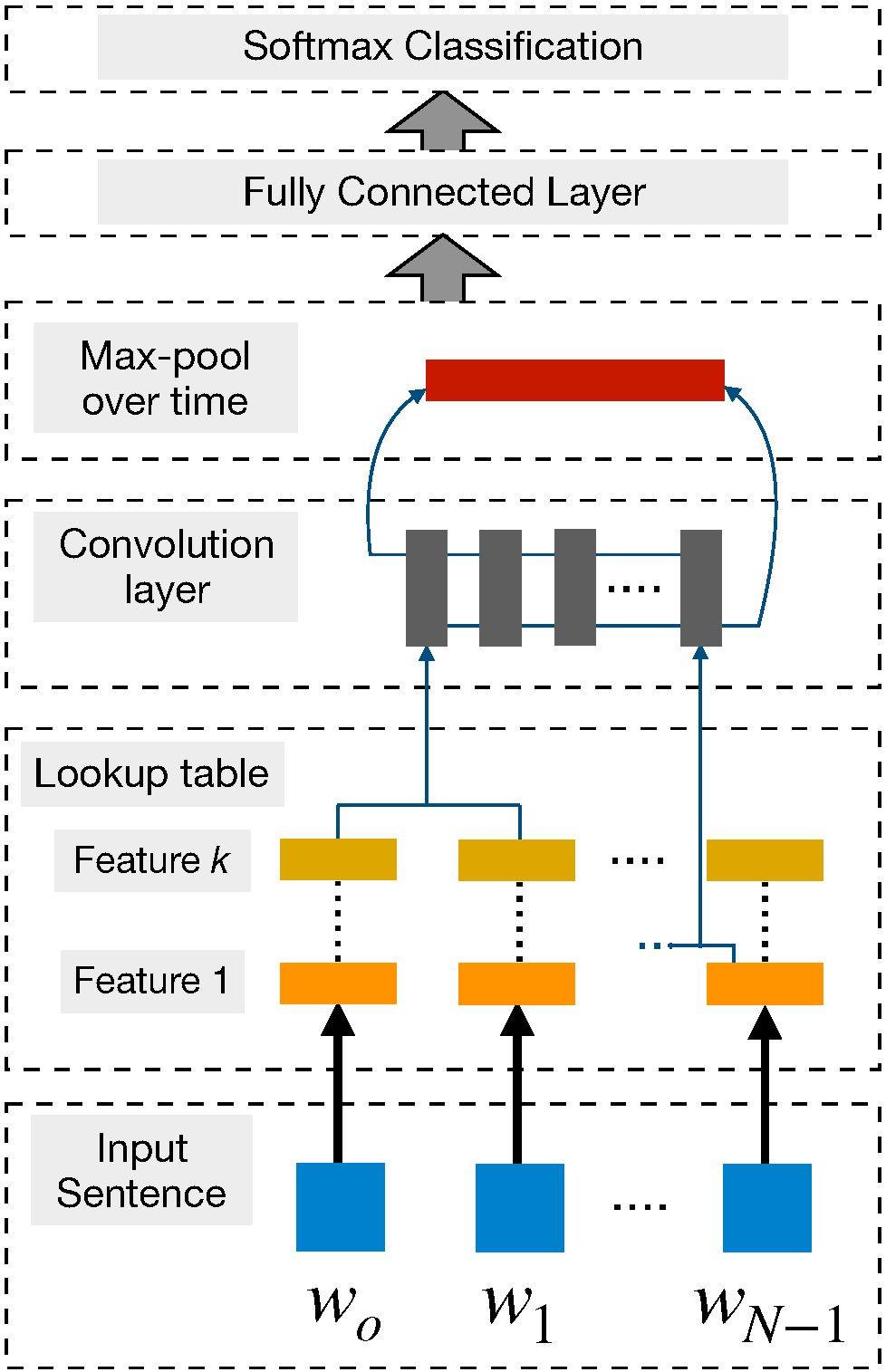
图 5:用于执行词级分类预测的 CNN 框架。(Collobert and Weston (2008))
使用 CNN 进行句子建模可以追溯到 Collobert 和 Weston (2008) 的研究,他们使用多任务学习为不同的 NLP 任务输出多个预测,如词性标注、语块分割、命名实体标签和语义相似词等。其中查找表可以将每一个词转换为一个用户自定义维度的向量。因此通过查找表,n 个词的输入序列 {s_1,s_2,… s_n } 能转换为一系列词向量 {w_s1, w_s2,… w_sn},这就是图 5 所示的输入。
这可以被认为是简单的词嵌入方法,其中权重都是通过网络来学习的。在 Collobert 2011 年的研究中,他扩展了以前的研究,并提出了一种基于 CNN 的通用框架来解决大量 NLP 任务,这两个工作都令 NLP 研究者尝试在各种任务中普及 CNN 架构。
CNN 具有从输入句子抽取 n-gram 特征的能力,因此它能为下游任务提供具有句子层面信息的隐藏语义表征。下面简单描述了一个基于 CNN 的句子建模网络到底是如何处理的。
基础 CNN
1. 序列建模
对于每一个句子,w_i∈R^d 表示句子中第 i 个词的词嵌入向量,其中 d 表示词嵌入的维度。给定有 n 个词的句子,句子能表示为词嵌入矩阵 W∈R^n×d。下图展示了将这样一个句子作为输入馈送到 CNN 架构中。
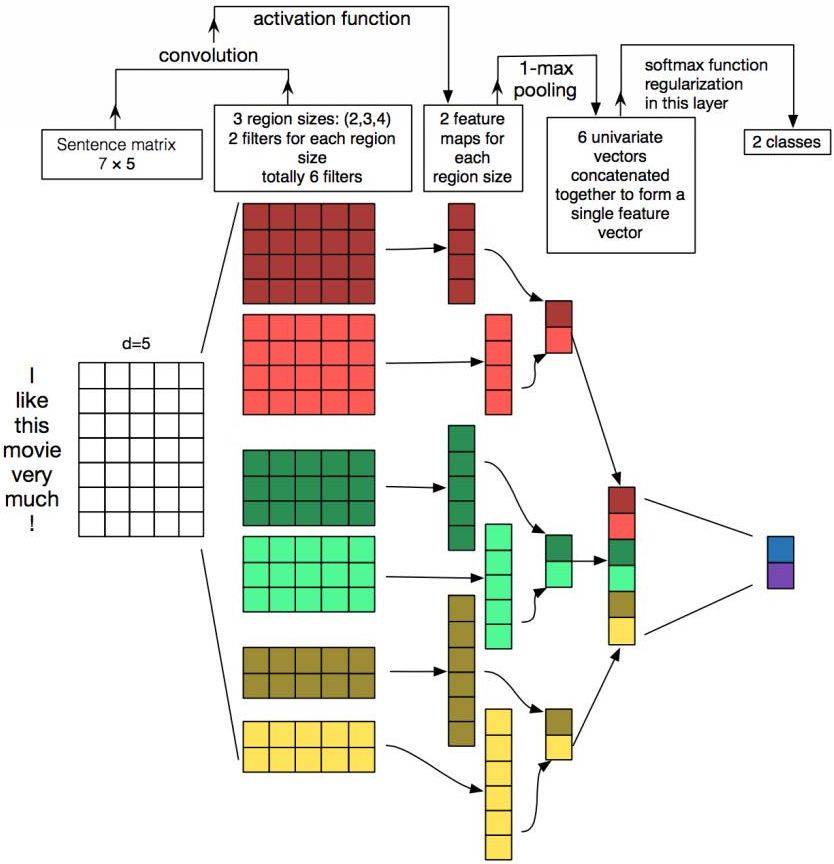
图 6:使用 CNN 的文本建模(Zhang and Wallace , 2015)。
若令 w_i:i+j 表示 w_i, w_i+1,…w_j 向量的拼接,那么卷积就可以直接在这个词嵌入输入层做运算。卷积包含 d 个通道的卷积核 k∈R^hd,它可以应用到窗口为 h 个词的序列上,并生成新的特征。例如,c_i 即使用卷积核在词嵌入矩阵上得到的激活结果:
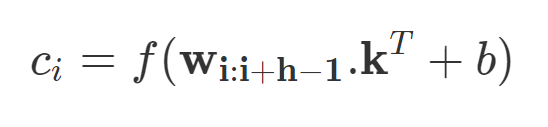
若 b 是偏置项,f 是非线性激活函数,例如双曲正切函数。使用相同的权重将滤波器 k 应用于所有可能的窗口,以创建特征图。
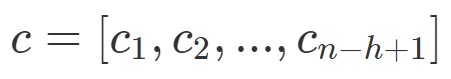
在卷积神经网络中,大量不同宽度的卷积滤波器(也叫做内核,通常有几百个)在整个词嵌入矩阵上滑动。每个内核提取一个特定的 n-gram 模式。卷积层之后通常是最大池化策略 c^=max{c},该策略通过对每个滤波器应用最大运算来对输入进行二次采样。使用这个策略有两大原因。
首先,最大池化提供固定长度的输出,这是分类所需的。因此,不管滤波器的大小如何,最大池化总是将输入映射到输出的固定维度上。其次,它在降低输出维度的同时保持了整个句子中最显著的 n-gram 特征。这是通过平移不变的方式实现的,每个滤波器都能从句子的任何地方提取特定的特征(如,否定),并加到句子的最终表示中。
词嵌入可以随机初始化,也可以在大型未标记语料库上进行预训练。第二种方法有时对性能提高更有利,特别是当标记数据有限时。卷积层和最大池化的这种组合通常被堆叠起来,以构建深度 CNN 网络。这些顺序卷积有助于改进句子的挖掘,以获得包含丰富语义信息的真正抽象表征。内核通过更深的卷积覆盖了句子的大部分,直到完全覆盖并创建了句子特征的总体概括。
2. 窗口方法
上述架构将完整句子建模为句子表征。然而,许多 NLP 任务(如命名实体识别,词性标注和语义角色标注)需要基于字的预测。为了使 CNN 适应这样的任务,需要使用窗口方法,其假定单词的标签主要取决于其相邻单词。因此,对于每个单词,存在固定大小的窗口,窗口内的子句都在处理的范围内。如前所述,独立的 CNN 应用于该子句,并且预测结果归因于窗口中心的单词。按照这个方法,Poira 等人(2016)采用多级深度 CNN 来标记句子中的每个单词为 aspect 或 non-aspect。结合一些语言模式,它们的集成分类器在 aspect 检测方面表现很好。
词级分类的最终目的通常是为整个句子分配一系列的标签。在这样的情况下,有时会采用结构化预测技术来更好地捕获相邻分类标签间的关系,最终生成连贯标签序列,从而给整个句子提供最大分数。
为了获得更大的上下文范围,经典窗口方法通常与时延神经网络(TDNN)相结合。这种方法中,可以在整个序列的所有窗口上进行卷积。通过定义特定宽度的内核,卷积通常会受到约束。因此,相较于经典窗口方法(只考虑要标记单词周围窗口中的单词),TDNN 会同时考虑句子中的所有单词窗口。TDNN 有时也能像 CNN 架构一样堆叠,以提取较低层的局部特征和较高层的总体特征。
应用
在这部分,研究者介绍了一些使用 CNN 来处理 NLP 任务的研究,这些研究在它们当时所处时代属于前沿。
Kim 探讨了使用上述架构进行各种句子分类任务,包括情感、主观性和问题类型分类,结果很有竞争力。因其简单有效的特点,这种方法很快被研究者接受。在针对特定任务进行训练之后,随机初始化的卷积内核成为特定 n-gram 的特征检测器,这些检测器对于目标任务非常有用。但是这个网络有很多缺点,最主要的一点是 CNN 没有办法构建长距离依存关系。

图 7:4 种预训练 7-gram 内核得到的最好核函数;每个内核针对一种特定 7-gram。
Kalchbrenner 等人的研究在一定程度上解决了上述问题。他们发表了一篇著名的论文,提出了一种用于句子语义建模的动态卷积神经网络(DCNN)。他们提出了动态 k-max 池化策略,即给定一个序列 p,选择 k 种最有效的特征。选择时保留特征的顺序,但对其特定位置不敏感。在 TDNN 的基础上,他们增加了动态 k-max 池化策略来创建句子模型。这种结合使得具有较小宽度的滤波器能跨越输入句子的长范围,从而在整个句子中积累重要信息。在下图中,高阶特征具有高度可变的范围,可能是较短且集中,或者整体的,和输入句子一样长。他们将模型应用到多种任务中,包括情感预测和问题类型分类等,取得了显著的成果。总的来说,这项工作在尝试为上下文语义建模的同时,对单个内核的范围进行了注释,并提出了一种扩展其范围的方法。
图 8:DCNN 子图,通过动态池化,较高层级上的宽度较小滤波器也能建立输入句子中的长距离相关性。
情感分类等任务还需要有效地抽取 aspect 与其情感极性(Mukherjee and Liu, 2012)。Ruder 等人(2016)还将 CNN 应用到了这类任务,他们将 aspect 向量与词嵌入向量拼接以作为输入,并获得了很好的效果。CNN 建模的方法一般因文本的长短而异,在较长文本上的效果比较短文本上好。Wang et al. (2015) 提出利用 CNN 建模短文本的表示,但是因为缺少可用的上下文信息,他们需要额外的工作来创建有意义的表征。因此作者提出了语义聚类,其引入了多尺度语义单元以作为短文本的外部知识。最后 CNN 组合这些单元以形成整体表示。
CNN 还广泛用于其它任务,例如 Denil et al. (2014) 利用 DCNN 将构成句子的单词含义映射到文本摘要中。其中 DCNN 同时在句子级别和文档级别学习卷积核,这些卷积核会分层学习并捕获不同水平的特征,因此 DCNN 最后能将底层的词汇特征组合为高级语义概念。
此外,CNN 也适用于需要语义匹配的 NLP 任务。例如我们可以利用 CNN 将查询与文档映射到固定维度的语义空间,并根据余弦相似性对与特定查询相关的文档进行排序。在 QA 领域,CNN 也能度量问题和实体之间的语义相似性,并借此搜索与问题相关的回答。机器翻译等任务需要使用序列信息和长期依赖关系,因此从结构上来说,这种任务不太适合 CNN。但是因为 CNN 的高效计算,还是有很多研究者尝试使用 CNN 解决机器翻译问题。
总体而言,CNN 在上下文窗口中挖掘语义信息非常有效,然而它们是一种需要大量数据训练大量参数的模型。因此在数据量不够的情况下,CNN 的效果会显著降低。CNN 另一个长期存在的问题是它们无法对长距离上下文信息进行建模并保留序列信息,其它如递归神经网络等在这方面有更好的表现。
第四章:循环神经网络
循环神经网络(RNN)的思路是处理序列信息。「循环」表示 RNN 模型对序列中的每一个实例都执行同样的任务,从而使输出依赖于之前的计算和结果。通常,RNN 通过将 token 挨个输入到循环单元中,来生成表示序列的固定大小向量。一定程度上,RNN 对之前的计算有「记忆」,并在当前的处理中使用对之前的记忆。该模板天然适合很多 NLP 任务,如语言建模、机器翻译、语音识别、图像字幕生成。因此近年来,RNN 在 NLP 任务中逐渐流行。
对 RNN 的需求
这部分将分析支持 RNN 在大量 NLP 任务中广泛使用的基本因素。鉴于 RNN 通过建模序列中的单元来处理序列,它能够捕获到语言中的内在序列本质,序列中的单元是字符、单词甚至句子。语言中的单词基于之前的单词形成语义,一个简单的示例是「dog」和「hot dog」。RNN 非常适合建模语言和类似序列建模任务中的此类语境依赖,这使得大量研究者在这些领域中使用 RNN,频率多于 CNN。
RNN 适合序列建模任务的另一个因素是它能够建模不定长文本,包括非常长的句子、段落甚至文档。与 CNN 不同,RNN 的计算步灵活,从而提供更好的建模能力,为捕获无限上下文创造了可能。这种处理任意长度输入的能力是使用 RNN 的主要研究的卖点之一。
很多 NLP 任务要求对整个句子进行语义建模。这需要在固定维度超空间中创建句子的大意。RNN 对句子的总结能力使得它们在机器翻译等任务中得到更多应用,机器翻译任务中整个句子被总结为固定向量,然后映射回不定长目标序列。
RNN 还对执行时间分布式联合处理(time distributed joint processing)提供网络支持,大部分序列标注任务(如词性标注)属于该领域。具体用例包括多标签文本分类、多模态情感分析等应用。
上文介绍了研究人员偏好使用 RNN 的几个主要因素。然而,就此认为 RNN 优于其他深度网络则大错特错。近期,多项研究就 CNN 优于 RNN 提出了证据。甚至在 RNN 适合的语言建模等任务中,CNN 的性能与 RNN 相当。CNN 与 RNN 在建模句子时的目标函数不同。RNN 尝试建模任意长度的句子和无限的上下文,而 CNN 尝试提取最重要的 n-gram。尽管研究证明 CNN 是捕捉 n-gram 特征的有效方式,这在特定长度的句子分类任务中差不多足够了,但 CNN 对词序的敏感度有限,容易限于局部信息,忽略长期依赖。
《Comparative Study of CNN and RNN for Natural Language Processing》对 CNN 和 RNN 的性能提供了有趣的见解。研究人员在多项 NLP 任务(包括情感分类、问答和词性标注)上测试后,发现没有明确的赢家:二者的性能依赖于任务所需的全局语义。
下面,我们讨论了文献中广泛使用的一些 RNN 模型。
RNN 模型
1. 简单 RNN
在 NLP 中,RNN 主要基于 Elman 网络,最初是三层网络。图 9 展示了一个较通用的 RNN,它按时间展开以适应整个序列。图中 x_t 作为网络在时间步 t 处的输入,s_t 表示在时间步 t 处的隐藏状态。s_t 的计算公式如下:
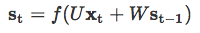
因此,s_t 的计算基于当前输入和之前时间步的隐藏状态。函数 f 用来做非线性变换,如 tanh、ReLU,U、V、W 表示在不同时间上共享的权重。在 NLP 任务中,x_t 通常由 one-hot 编码或嵌入组成。它们还可以是文本内容的抽象表征。o_t 表示网络输出,通常也是非线性的,尤其是当网络下游还有其他层的时候。
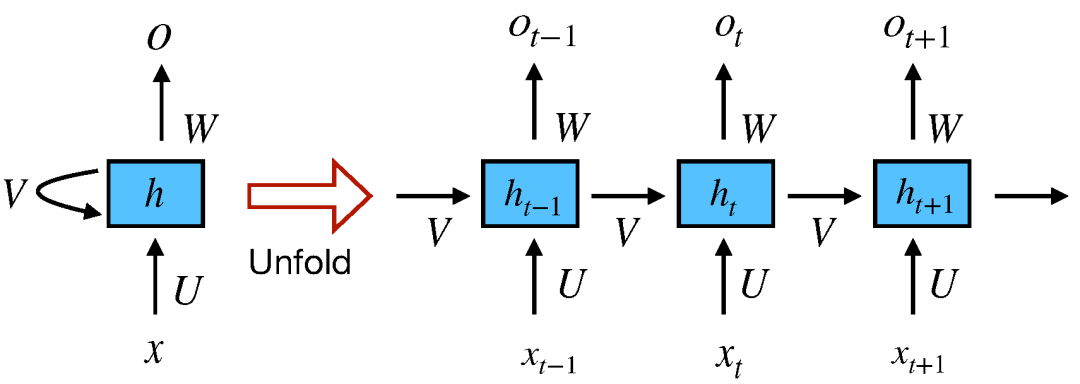
图 9:简单 RNN 网络(图源:https://www.nature.com/articles/nature14539)
RNN 的隐藏状态通常被认为是其最重要的元素。如前所述,它被视为 RNN 的记忆元素,从其他时间步中累积信息。但是,在实践中,这些简单 RNN 网络会遇到梯度消失问题,使学习和调整网络之前层的参数变得非常困难。
该局限被很多网络解决,如长短期记忆网络(LSTM)、门控循环单元(GRU)和残差网络(ResNet),前两个是 NLP 应用中广泛使用的 RNN 变体。
2. 长短期记忆(LSTM)
LSTM 比简单 RNN 多了『遗忘』门,其独特机制帮助该网络克服了梯度消失和梯度爆炸问题。
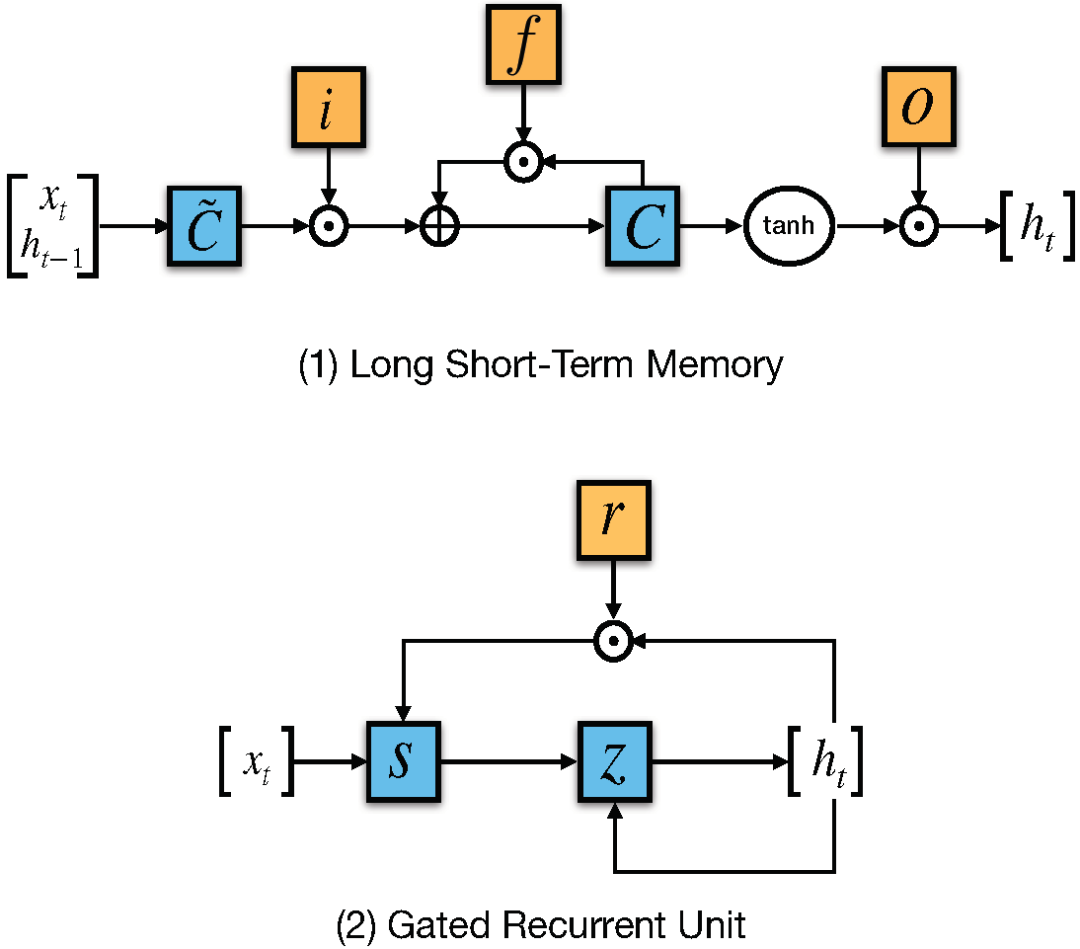
图 10:LSTM 和 GRU 门图示(图源:https://arxiv.org/abs/1412.3555)
与原版 RNN 不同,LSTM 允许误差通过无限数量的时间步进行反向传播。它包含三个门:输入门、遗忘门和输出门,并通过结合这三个门来计算隐藏状态,如下面的公式所示:
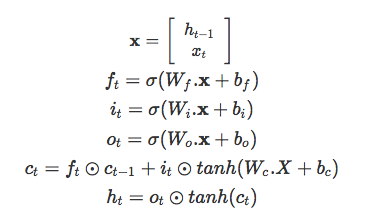
3. 门控循环单元(GRU)
另一个门控 RNN 变体是 GRU,复杂度更小,其在大部分任务中的实验性能与 LSTM 类似。GRU 包括两个门:重置门和更新门,并像没有记忆单元的 LSTM 那样处理信息流。因此,GRU 不加控制地暴露出所有的隐藏内容。由于 GRU 的复杂度较低,它比 LSTM 更加高效。其工作原理如下:
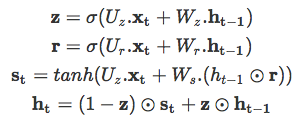
研究者通常面临选择合适门控 RNN 的难题,这个问题同样困扰 NLP 领域开发者。纵观历史,大部分对 RNN 变体的选择都是启发式的。《Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling》对前面三种 RNN 变体进行了对比评估,不过评估不是在 NLP 任务上进行的,而是复调音乐建模和语音信号建模相关任务。他们的评估结果明确表明门控单元(LSTM 和 GRU)优于传统的简单 RNN(实验中用的是 tanh 激活函数),如下图所示。但是,他们对这两种门控单元哪个更好没有定论。其他研究也注意到了这一点,因此人们在二者之间作出选择时通常利用算力等其他因素。
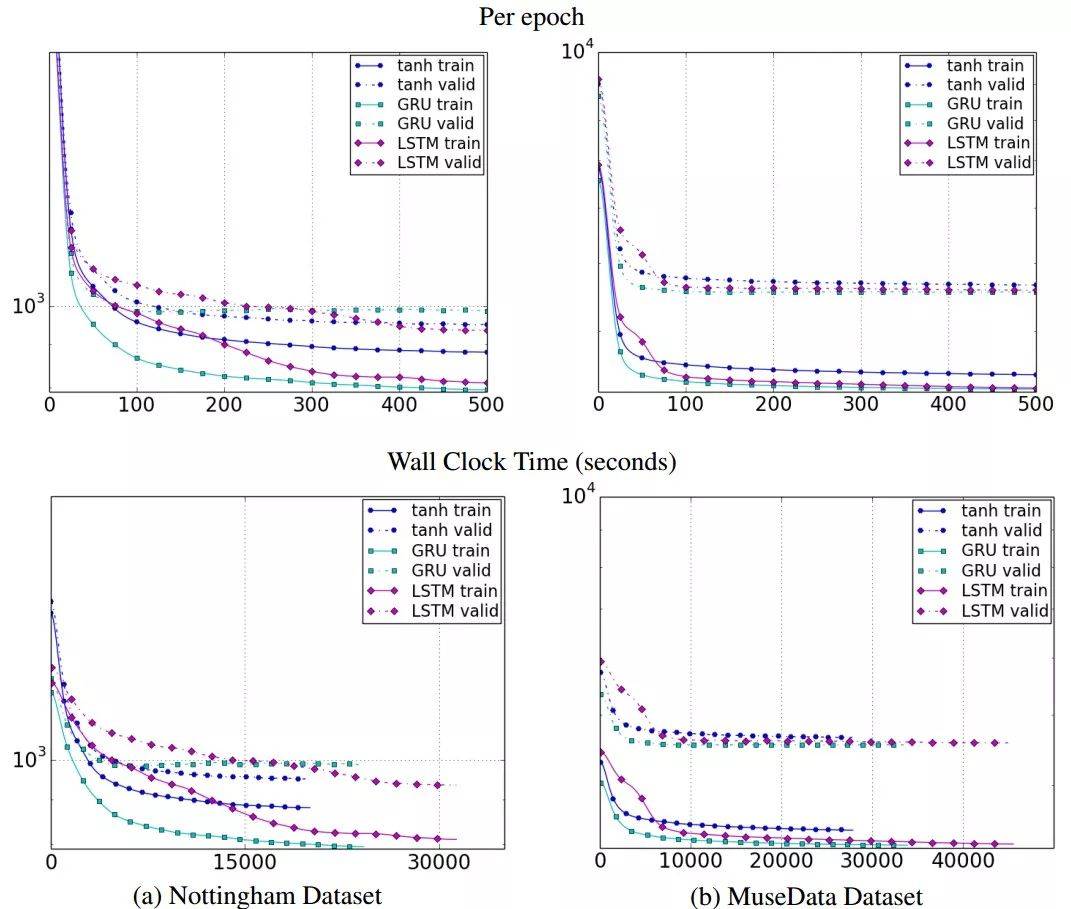
图 11:不同 RNN 变体在训练集和验证集上的学习曲线,上图 x 轴表示迭代次数,下图 x 轴表示挂钟时间,y 轴表示模型的负对数似然(以对数标尺显示)。
应用
1. 用于单词级别分类任务的 RNN
之前,RNN 经常出现在单词级别的分类任务中。其中的很多应用到现在仍然是所在任务中的最优结果。论文《Neural Architectures for Named Entity Recognition》提出 LSTM+CRF 架构。它使用双向 LSTM 解决命名实体识别问题,该网络捕捉目标单词周围的任意长度上下文信息(缓解了固定窗口大小的约束),从而生成两个固定大小的向量,再在向量之上构建另一个全连接层。最终的实体标注部分使用的是 CRF 层。
RNN 在语言建模任务上也极大地改善了基于 count statistics 的传统方法。该领域的开创性研究是 Alex Graves 2013 年的研究《Generating Sequences With Recurrent Neural Networks》,介绍了 RNN 能够有效建模具备长距离语境结构的复杂序列。该研究首次将 RNN 的应用扩展到 NLP 以外。之后,Sundermeyer 等人的研究《From Feedforward to Recurrent LSTM Neural Networks for Language Modeling》对比了在单词预测任务中用 RNN 替换前馈神经网络获得的收益。该研究提出一种典型的神经网络层级架构,其中前馈神经网络比基于 count 的传统语言模型有较大改善,RNN 效果更好,LSTM 的效果又有改进。该研究的一个重点是他们的结论可应用于多种其他任务,如统计机器翻译。
2. 用于句子级别分类任务的 RNN
Xin Wang 等人 2015 年的研究《Predicting Polarities of Tweets by Composing Word Embeddings with Long Short-Term Memory》提出使用 LSTM 编码整篇推文(tweet),用 LSTM 的隐藏状态预测情感极性。这种简单的策略被证明与 Nal Kalchbrenner 等人 2014 年的研究《A Convolutional Neural Network for Modelling Sentences》提出的较复杂 DCNN 结构性能相当,DCNN 旨在使 CNN 模型具备捕捉长期依赖的能力。在一个研究否定词组(negation phrase)的特殊案例中,Xin Wang 等人展示了 LSTM 门的动态可以捕捉单词 not 的反转效应。
与 CNN 类似,RNN 的隐藏状态也可用于文本之间的语义匹配。在对话系统中,Lowe 等人 2015 年的研究《The Ubuntu Dialogue Corpus: A Large Dataset for Research in Unstructured Multi-Turn Dialogue Systems》提出用 Dual-LSTM 匹配信息和候选回复,Dual-LSTM 将二者编码为固定大小的向量,然后衡量它们的内积用于对候选回复进行排序。
3. 用于生成语言的 RNN
NLP 领域中的一大难题是生成自然语言,而这是 RNN 另一个恰当的应用。基于文本或视觉数据,深度 LSTM 在机器翻译、图像字幕生成等任务中能够生成合理的任务特定文本。在这些案例中,RNN 作为解码器。
在 Ilya Sutskever 等人 2014 年的研究《Sequence to Sequence Learning with Neural Networks》中,作者提出了一种通用深度 LSTM 编码器-解码器框架,可以实现序列之间的映射。使用一个 LSTM 将源序列编码为定长向量,源序列可以是机器翻译任务中的源语言、问答任务中的问题或对话系统中的待回复信息。然后将该向量作为另一个 LSTM(即解码器)的初始状态。在推断过程中,解码器逐个生成 token,同时使用最后生成的 token 更新隐藏状态。束搜索通常用于近似最优序列。
该研究使用了一个 4 层 LSTM 在机器翻译任务上进行端到端实验,结果颇具竞争力。《A Neural Conversational Model》使用了同样的编码器-解码器框架来生成开放域的有趣回复。使用 LSTM 解码器处理额外信号从而获取某种效果现在是一种普遍做法了。《A Persona-Based Neural Conversation Model》提出用解码器处理恒定人物向量(constant persona vector),该向量捕捉单个说话人的个人信息。在上述案例中,语言生成主要基于表示文本输入的语义向量。类似的框架还可用于基于图像的语言生成,使用视觉特征作为 LSTM 解码器的初始状态(图 12)。
视觉 QA 是另一种任务,需要基于文本和视觉线索生成语言。2015 年的论文《Ask Your Neurons: A Neural-based Approach to Answering Questions about Images》是首个提供端到端深度学习解决方案的研究,他们使用 CNN 建模输入图像、LSTM 建模文本,从而预测答案(一组单词)。
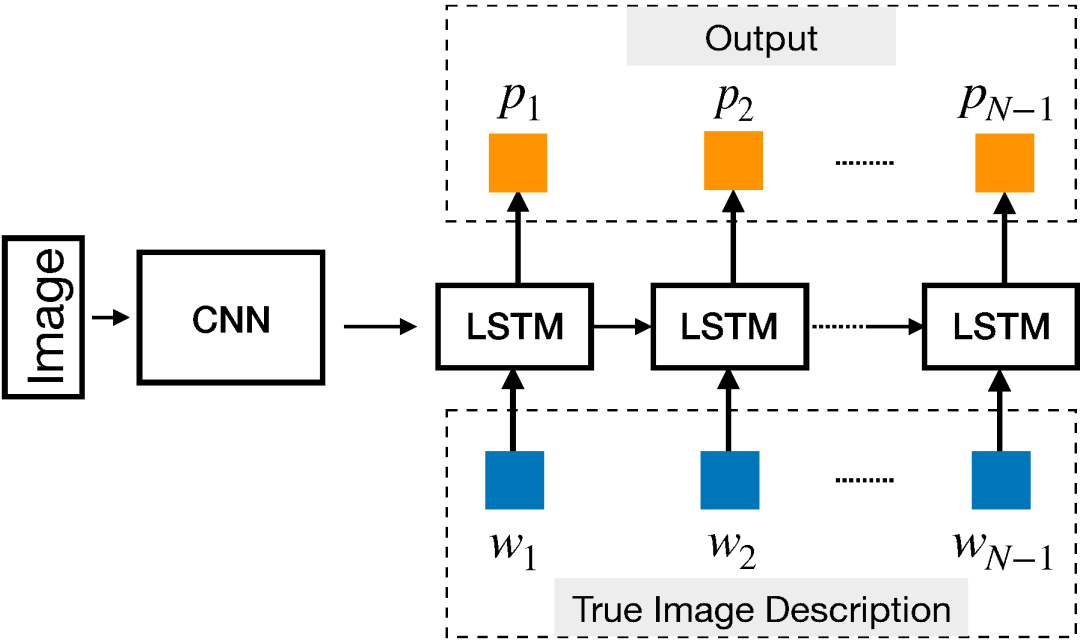
图 12:结合 LSTM 解码器和 CNN 图像嵌入器,生成图像字幕(图源:https://www.cv-foundation.org/openaccess/content_cvpr_2015/papers/Vinyals_Show_and_Tell_2015_CVPR_paper.pdf)
《Ask Me Anything: Dynamic Memory Networks for Natural Language Processing》提出动态记忆网络(dynamic memory network,DMN)来解决这个问题。其思路是重复关注输入文本和图像,以使每次迭代中的信息都得到改善。注意力网络用于关注输入文本词组。
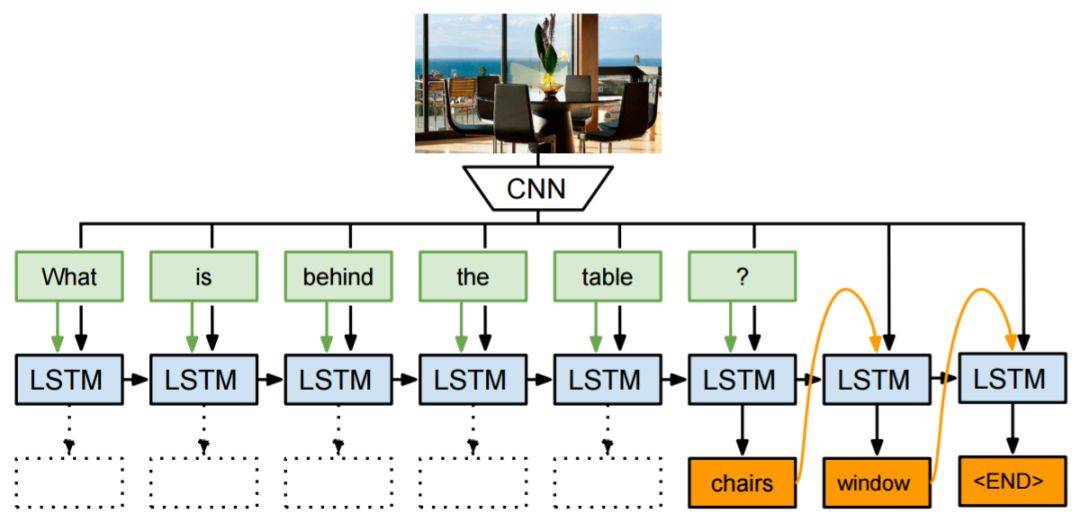
图 13:神经图像 QA(图源:https://www.cv-foundation.org/openaccess/content_iccv_2015/papers/Malinowski_Ask_Your_Neurons_ICCV_2015_paper.pdf)
注意力机制
传统编码器-解码器框架的一个潜在问题是:有时编码器会强制编码可能与目前任务不完全相关的信息。这个问题在输入过长或信息量过大时也会出现,选择性编码是不可能的。
例如,文本摘要任务可以被视为序列到序列的学习问题,其中输入是原始文本,输出是压缩文本。直观上看,让固定大小向量编码长文本中的全部信息是不切实际的。类似的问题在机器翻译任务中也有出现。
在文本摘要和机器翻译等任务中,输入文本和输出文本之间存在某种对齐,这意味着每个 token 生成步都与输入文本的某个部分高度相关。这启发了注意力机制。该机制尝试通过让解码器回溯到输入序列来缓解上述问题。具体在解码过程中,除了最后的隐藏状态和生成 token 以外,解码器还需要处理基于输入隐藏状态序列计算出的语境向量。
《Neural Machine Translation by Jointly Learning to Align and Translate》首次将注意力机制应用到机器翻译任务,尤其改进了在长序列上的性能。该论文中,关注输入隐藏状态序列的注意力信号由解码器最后的隐藏状态的多层感知机决定。通过在每个解码步中可视化输入序列的注意力信号,可以获得源语言和目标语言之间的清晰对齐(图 14)。
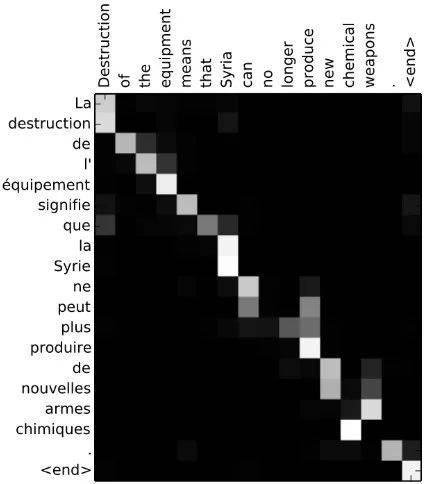
图 14:词对齐矩阵(图源:https://arxiv.org/abs/1409.0473)
类似的方法也被应用到摘要任务中,《A Neural Attention Model for Abstractive Sentence Summarization》用注意力机制处理输入句子从而得到摘要中的每个输出单词。作者执行 abstractive summarization,它与 extractive summarization 不同,但可以扩展到具备最小语言输入的大型数据。
在图像字幕生成任务中,《Show, Attend and Tell: Neural Image Caption Generation with Visual Attention》用 LSTM 解码器在每个解码步中处理输入图像的不同部分。注意力信号由之前的隐藏状态和 CNN 特征决定。《Grammar as a Foreign Language》将解析树线性化,从而将句法解析问题作为序列到序列学习任务。该研究证明注意力机制更加数据高效。指回输入序列的进一步步骤是:在特定条件下,直接将输入中的单词或子序列复制到输出序列,这在对话生成和文本摘要等任务中也有用。解码过程中的每个时间步可以选择复制还是生成。(参见:新闻太长不想看?深度解析 MetaMind 文本摘要新研究)
在基于 aspect 的情感分析中,《Attention-based LSTM for Aspect-level Sentiment Classification》提出基于注意力的解决方案,使用 aspect 嵌入为分类提供额外支持(图 15)。注意力模块选择性关注句子的某些区域,这会影响 aspect 的分类。图 16 中,对于 a 中的 aspect「service」,注意力模块动态聚焦词组「fastest delivery times」,b 中对于 aspect「food」,注意力在整个句子中识别了多个关键点,包括「tasteless」和「too sweet」。近期,《Targeted Aspect-Based Sentiment Analysis via Embedding Commonsense Knowledge into an Attentive LSTM》用层级注意力机制(包含目标级注意力和句子级注意力)增强 LSTM,利用常识处理基于目标 aspect 的情感分析。
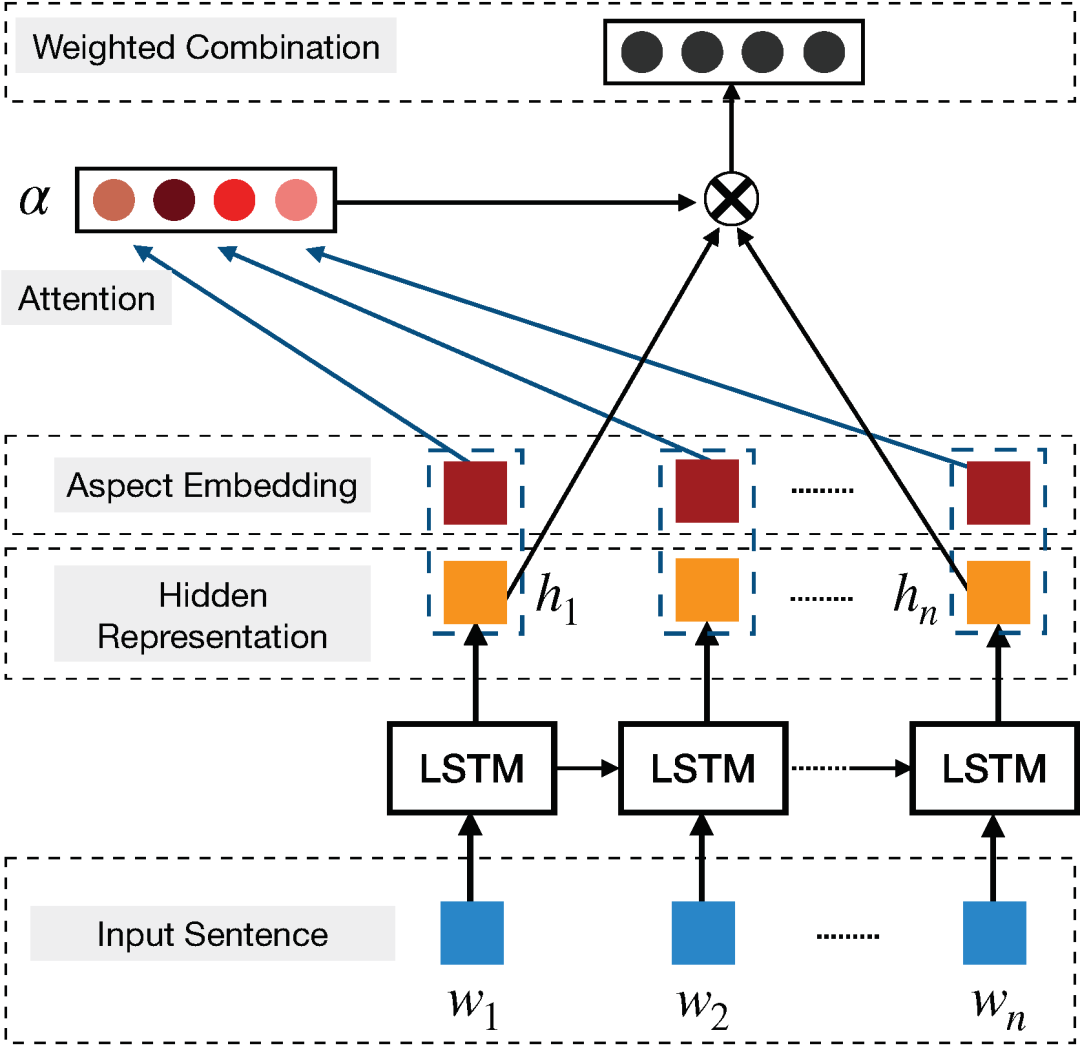
图 15:使用注意力机制进行 aspect 分类(图源:https://aclanthology.coli.uni-saarland.de/papers/D16-1058/d16-1058)

图 16:对于特定 aspect,注意力模块对句子的关注点(图源:https://aclanthology.coli.uni-saarland.de/papers/D16-1058/d16-1058)
另一方面,《Aspect Level Sentiment Classification with Deep Memory Network》采用基于记忆网络(也叫 MemNet)的解决方案,使用多跳注意力(multiple-hop attention)。记忆网络上的多个注意力计算层可以改善对记忆中大部分信息区域的查找,从而有助于分类。这一研究目前仍是该领域的当前最优结果。
由于注意力模块应用的直观性,NLP 研究者和开发者在越来越多的应用中积极使用注意力模块。
并行化注意力:Transformer
CNN 和 RNN 在包括编码器-解码器架构在内的序列传导应用中非常关键。注意力机制可以进一步提升这些模型的性能。但是,这些架构面临的一个瓶颈是编码步中的序列处理。为了解决该问题,《Attention Is All You Need》提出了 Transformer,它完全去除了编码步中的循环和卷积,仅依赖注意力机制来捕捉输入和输出之间的全局关系。因此,整个架构更加并行化,在翻译、解析等任务上训练得到积极结果所需的时间也更少。
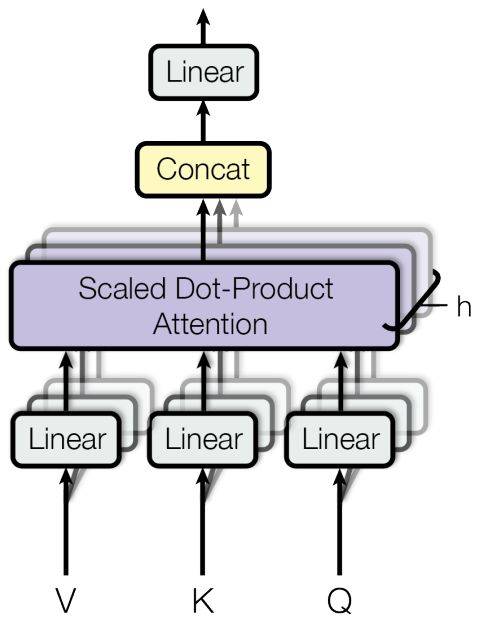
图 17:multi-head 注意力(图源:https://arxiv.org/abs/1706.03762)
Transformer 的编码器和解码器部分都有一些堆叠层。每个层有两个由 multi-head 注意力层组成的子层(图 17),之后是 position-wise 前馈网络。对于查询集 Q、关键 K 和值 V,multi-head 注意力模块执行注意力 h 次,计算公式如下:

此处,W_i^{[.]} 和 W^o 是投影参数。该模型融合了残差连接、层归一化、dropout、位置编码等技术,在英语-德语、英语-法语翻译和 constituency parsing 中获得了当前最优结果。
第八章:不同模型在不同 NLP 任务上的表现
在下面表 2 到表 7 中,我们总结了一系列深度学习方法在标准数据集上的表现,这些数据集都是近年来最流行的探究主题。我们的目标是向读者展示深度学习社区常用的数据集以及不同模型在这些数据集上的当前最佳结果。
词性标注
WSJ-PTB(the Wall Street Journal part of the Penn Treebank Dataset)语料库包含 117 万个 token,已被广泛用于开发和评估词性标注系统。Giménez 和 arquez(2004)在 7 个单词窗口内采用了基于人工特征的一对多 SVM,其中有些基本的 n-gram 模式被评估用来构成二元特征,如:「前一个单词是 the」,「前两个标签是 DT NN」等。词性标注问题的一大特征是相邻标签之间的强依赖性。通过简单的从左到右标注方案,该方法仅通过特征工程建模相邻标签之间的依赖性。
为了减少特征工程,Collobert 等人(2011)通过多层感知机仅依赖于单词窗口中的词嵌入。Santos 和 Zadrozny(2014)将词嵌入和字符嵌入连接起来,以便更好地利用形态线索。在论文《Learning Character-level Representations for Part-of-Speech Tagging》中,他们没有考虑 CRF,但由于单词级的决策是在上下文窗口上做出的,可以看到依赖性被隐式地建模。Huang 等人(2015)把单词嵌入和手动设计的单词级特征连接起来,并采用双向 LSTM 来建模任意长度的上下文。
一系列消融分析(ablative analysis)表明,双向 LSTM 和 CRF 都提升了性能。Andor 等人(2016)展示了一种基于转换(transition-based)的方法,该方法通过简单的前馈神经网络上产生了具有竞争性的结果。当应用于序列标注任务时,DMN(Kumar et al., 2015)允许通过把每个 RNN 的隐藏状态视为记忆实体来多次关注上下文,且每次都关注于上下文的不同部分。
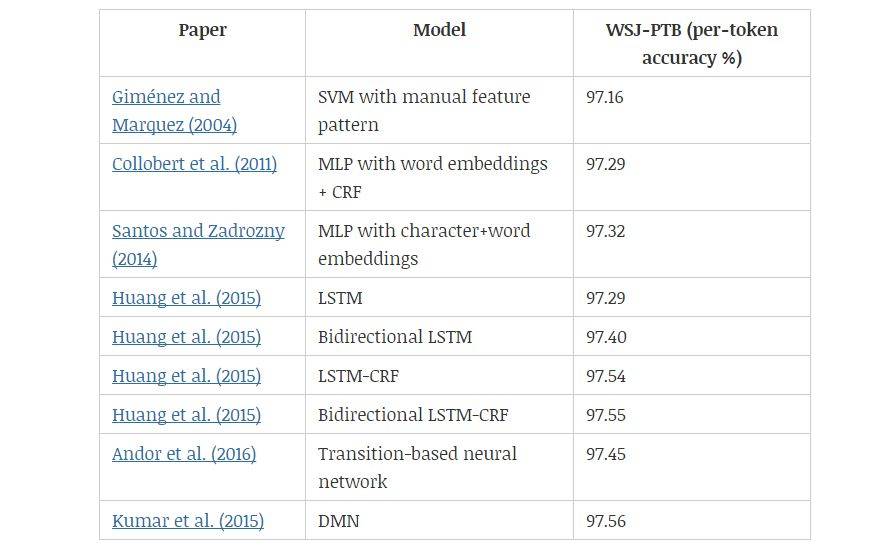
表 2:词性标注
句法分析
有两种句法分析:依存句法分析(dependency parsing)和成分句法分析(constituency parsing)。前者将单个单词及其关系联系起来,后者依次将文本拆分成子短语(sub-phrase)。基于转换的方法是很多人的选择,因为它们在句子长度上是线性的。解析器(parser)会做出一系列决定:根据缓冲器(buffer)顺序读取单词,然后逐渐将它们组合到句法结构中(Chen and Manning, 2014)。
在每个时间步,决策是基于包含可用树节点的堆栈、包含未读单词的缓冲器和获得的依存关系集来确定的。Chen and Manning 利用带有一个隐藏层的神经网络来建模每个时间步做出的决定。输入层包含特定单词、词性标注和弧标签的嵌入向量,这些分别来自堆栈、缓冲器和依存关系集。
Tu 等人(2015)扩展了 Chen and Manning 的工作,他们用了带有两个隐藏层的深度模型。但是,不管是 Tu 等人还是 Chen 和 Manning,他们都依赖于从解析器状态中选择手动特征,而且他们只考虑了少数最后的几个 token。Dyer 等人(2015)提出堆栈-LSTMs 来建模任意长度的 token 序列。当我们对树节点的堆栈进行 push 或 pop 时,堆栈的结束指针(end pointer)会改变位置。Zhou 等人(2017)整合集束搜索和对比学习,以实现更好的优化。
基于变换的模型也被应用于成分句法分析。Zhu 等人(2013)基于堆栈和缓冲器顶部几个单词的特征(如词性标签、成分标签)来进行每个转换动作。通过用线性标签序列表示解析树,Vinyals 等人(2015)将 seq2seq 学习方法应用于该问题。

表 3.1:依存句法分析(UAS/LAS=未标记/标记的 Attachment 分数;WSJ=The Wall Street Journal Section of Penn Treebank)

表 3.2:成分句法分析
命名实体识别
CoNLL 2003 是用于命名实体识别(NER)的标准英语数据集,其中主要包含四种命名实体:人、地点、组织和其它实体。NER 属于自然语言处理问题,其中词典非常有用。Collobert 等人(2011)首次通过用地名索引特征增强的神经架构实现了具有竞争性的结果。Chiu and Nichols(2015)将词典特征、字符嵌入和单词嵌入串联起来,然后将其作为双向 LSTM 的输入。
另一方面,Lample 等人(2016)仅靠字符和单词嵌入,通过在大型无监督语料库上进行预训练嵌入实现了具有竞争性的结果。与 POS 标签类似,CRF 也提升了 NER 的性能,这一点在 Lample 等人(2016)的《Neural Architectures for Named Entity Recognition》中得到了证实。总体来说,带有 CRF 的双向 LSTM 对于结构化预测是一个强有力的模型。
Passos 等人(2014)提出经修正的 skip-gram 模型,以更好地学习与实体类型相关的词嵌入,此类词嵌入可以利用来自相关词典的信息。Luo 等人(2015)联合优化了实体以及实体和知识库的连接。Strubell 等人(2017)提出用空洞卷积,他们希望通过跳过某些输入来定义更宽的有效输入,因此实现更好的并行化和上下文建模。该模型在保持准确率的同时展示出了显著的加速。
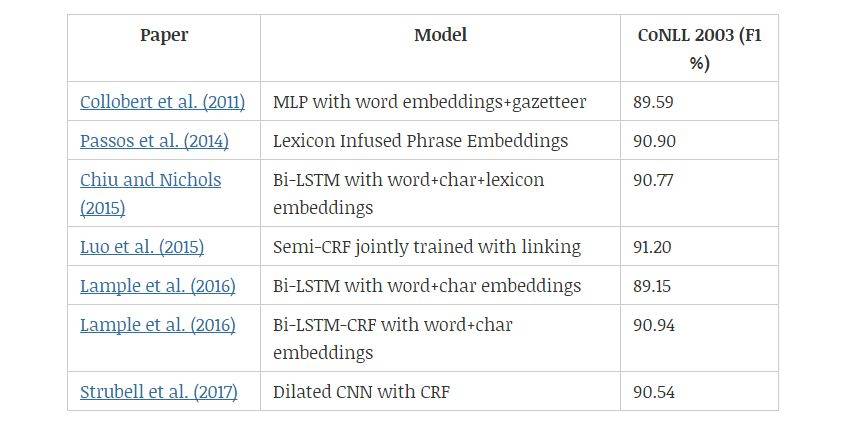
表 4:命名实体识别
语义角色标注
语义角色标注(SRL)旨在发现句子中每个谓词的谓词-论元(predicate-argument)结构。至于每个目标动词(谓语),句子中充当动词语义角色的所有成分都会被识别出来。典型的语义论元包括施事者、受事者、工具等,以及地点、时间、方式、原因等修饰语 (Zhou and Xu, 2015)。表 5 展示了不同模型在 CoNLL 2005 & 2012 数据集上的性能。
传统 SRL 系统包含几个阶段:生成解析树,识别出哪些解析树节点代表给定动词的论元,最后给这些节点分类以确定对应的 SRL 标签。每个分类过程通常需要抽取大量特征,并将其输入至统计模型中(Collobert et al., 2011)。
给定一个谓词,Täckström 等人(2015)基于解析树,通过一系列特征对该谓词的组成范围以及该范围与该谓词的可能关系进行打分。他们提出了一个动态规划算法进行有效推断。Collobert 等人(2011)通过解析以附加查找表形式提供的信息,并用卷积神经网络实现了类似的结果。Zhou 和 Xu(2015)提出用双向 LSTM 来建模任意长度的上下文,结果发现不使用任何解析树的信息也是成功的。
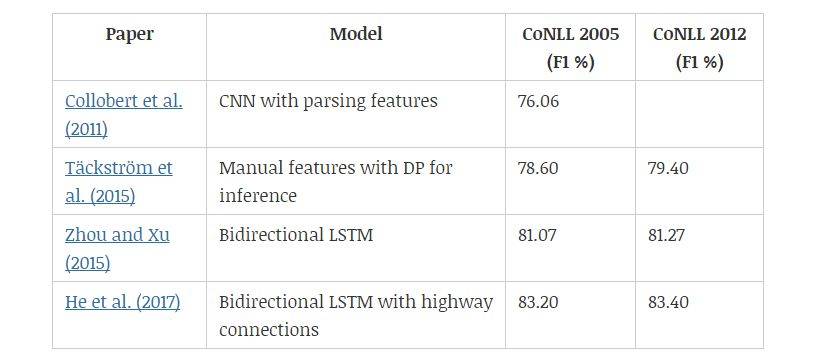
表 5:语义角色标注
情感分类
SST 数据集(Stanford Sentiment Treebank)包含从电影评论网 Rotten Tomatoe 上收集的句子。它由 Pang 和 Lee(2005)提出,后来被 Socher 等人(2013)进一步拓展。该数据集的标注方案启发了一个新的情感分析数据集——CMU-MOSI,其中模型需要在多模态环境中研究情感倾向。
Socher 等人(2013)和 Tai 等人(2015)都是通过成分解析树及递归神经网络来改善语义表征。另一方面,树形 LSTM(tree-LSTM)比线性双向 LSTM 表现更好,说明树结构能够更好地捕捉自然句子的句法特性。Yu 等人(2017)提出用情感词汇微调预训练的词嵌入,然后基于 Tai 等人(2015)的研究观察改进结果。
Kim(2014)和 l Kalchbrenner 等人(2014)都使用卷积层。Kim 等人提出的模型与图 5 中的相似,而 Kalchbrenner 等人通过将 k-max 池化层和卷积层交替使用,以分层方式构建模型。
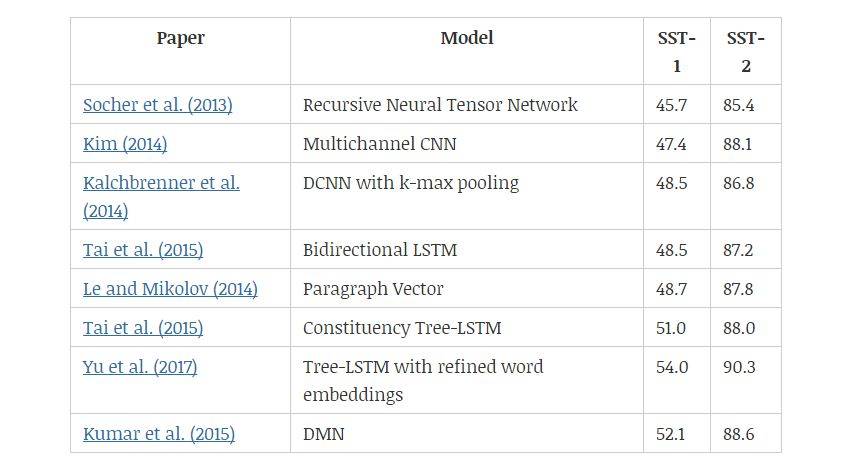
表 6:不同情感分类模型在 SST-1 和 SST-2 数据集上的效果。
机器翻译
基于短语的 SMT 框架(Koehn et al., 2003)将翻译模型分解为原语短语和目标语短语之间的概率匹配问题。Cho et al. (2014) 进一步提出用 RNN 编码器-解码器框架学习原语与目标语的匹配概率。而基于循环神经网络的编码器-解码器架构,再加上注意力机制在一段时间内成为了业内最标准的架构。Gehring et al. (2017) 提出了基于 CNN 的 Seq2Seq 模型,CNN 以并行的方式利用注意力机制计算每一个词的表征,解码器再根据这些表征确定目标语序列。Vaswani et al. (2017) 随后提出了完全基于注意力机制的 Transformer,它目前已经是神经机器翻译最常见的架构了。
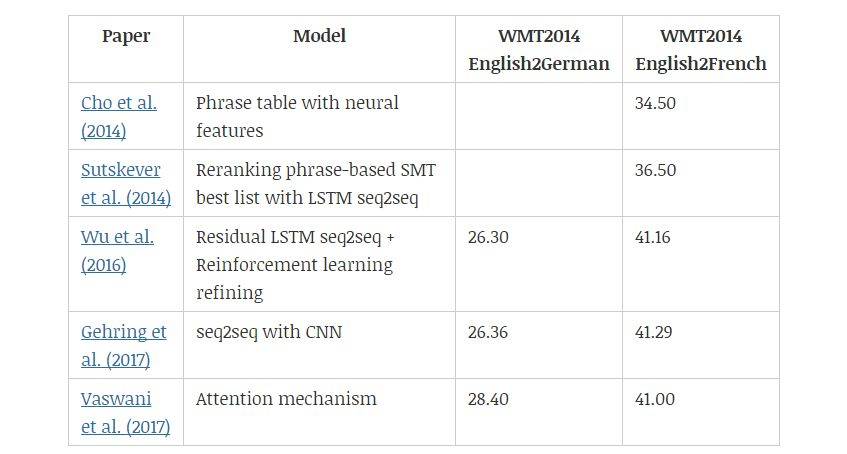
表 7:不同机器翻译模型和 BLEU 值。
问答系统
QA 问题有多种形式,有的研究者根据大型知识库来回答开放性问题,也有的研究者根据模型对句子或段落的理解回答问题。对于基于知识库的问答系统,学习回答单关系查询的核心是数据库中找到支持的事实。
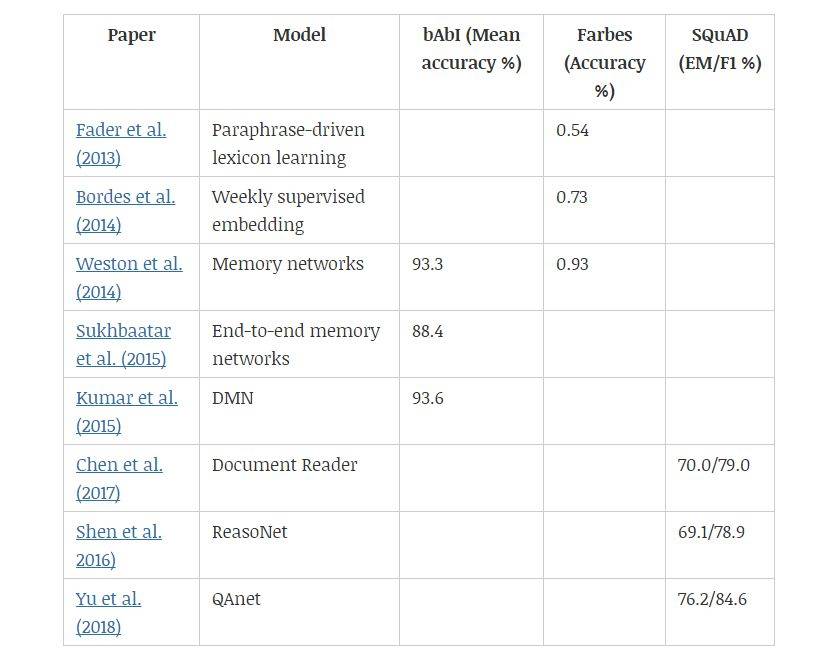
表 8:不同模型在不同问答数据集上的效果。
上下文嵌入
2018 年,使用预训练的语言模型可能是 NLP 领域最显著的趋势,它可以利用从无监督文本中学习到的「语言知识」,并迁移到各种 NLP 任务中。这些预训练模型有很多,包括 ELMo、ULMFiT、OpenAI Transformer 和 BERT,其中又以 BERT 最具代表性,它在 11 项 NLP 任务中都获得当时最佳的性能。不过目前有 9 项任务都被微软的新模型超过。下图展示了不同模型在 12 种 NLP 任务中的效果:
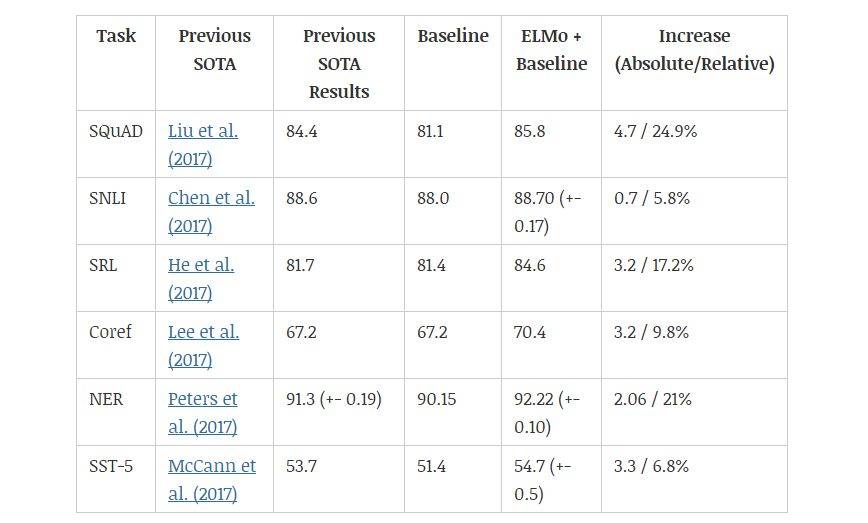
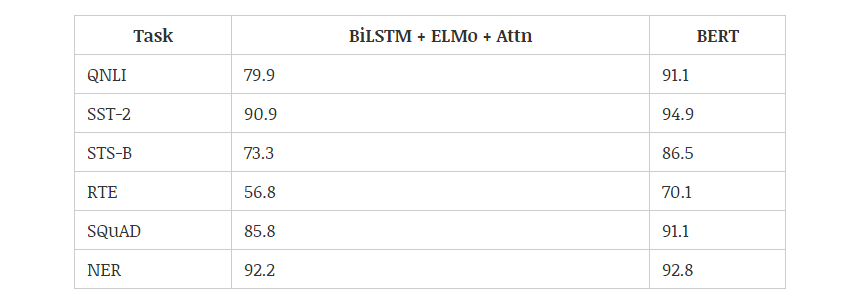
机器之心曾解读过 BERT 的的核心过程,它会先从数据集抽取两个句子,其中第二句是第一句的下一句的概率是 50%,这样就能学习句子之间的关系。其次随机去除两个句子中的一些词,并要求模型预测这些词是什么,这样就能学习句子内部的关系。最后再将经过处理的句子传入大型 Transformer 模型,并通过两个损失函数同时学习上面两个目标就能完成训练。
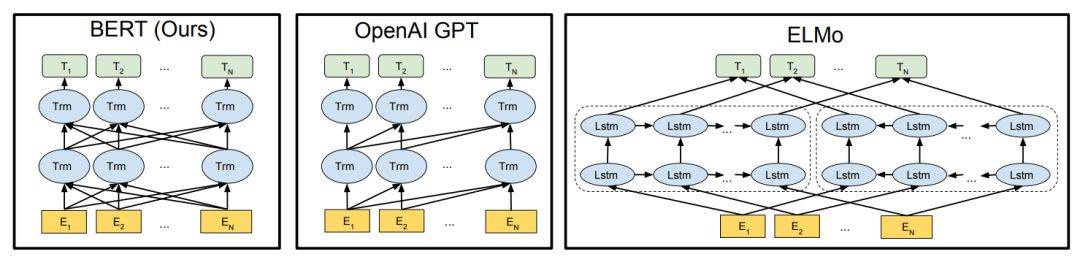
如上所示为不同预训练模型的架构,BERT 可以视为结合了 OpenAI GPT 和 ELMo 优势的新模型。其中 ELMo 使用两条独立训练的 LSTM 获取双向信息,而 OpenAI GPT 使用新型的 Transformer 和经典语言模型只能获取单向信息。
BERT 的主要目标是在 OpenAI GPT 的基础上对预训练任务做一些改进,以同时利用 Transformer 深度模型与双向信息的优势。这种「双向」的来源在于 BERT 与传统语言模型不同,它不是在给定所有前面词的条件下预测最可能的当前词,而是随机遮掩一些词,并利用所有没被遮掩的词进行预测。
原文链接:https://nlpoverview.com/